论文笔记-Training data-efficient image transformers & distillation through attention
论文链接:https://arxiv.org/abs/2012.12877
1. 前言
自从ViT提出以来,大量的视觉工作者拥入了Transformer系列的怀抱,在知乎上有这样一个提问:在CV界,传统卷积已经彻底输给Transformer了吗?答者们从很多不同的角度回答了这个问题,有从新的ConvNext刷点来回答的,也有从工业界实用角度来回答的,其中也不乏说将CNN与Transformer组合起来使用的。但DeiT(ICML 2021)这篇论文从知识蒸馏的角度将CNN和Transformer结合了起来,使得ViT的训练更加“平民化”,不需要巨量的数据也可以获得很好的效果。
2. 摘要
目前的Vision Transformer结构极度依赖于大规模的数据集和海量的模型参数,因此限制了ViT的应用。在ViT的论文中,使用JFT-300M数据集,用2500个TPU days(即单个TPU上训练2500天)才能在ImageNet上取得88.55%准确率的效果。绝大部分的工作者是无法达到这种实验条件的,并且JFT-300M(3亿张图片)这个数据集并没有开源,所以基于如此庞大数据集的work基本无法进行。DeiT(Data-efficient image transformers)基于这种情况,提出了一种无卷积(convolution free)的结构,在ImageNet上不用额外数据,只用一台计算机训练两到三天,用86M的参数量就可以达到83.1%的准确率。DeiT使用的基本策略是知识蒸馏(knowledge distillation),通过在输入端加入一个distillation token来保证transformer student model可以从convnet teacher model中学到知识。
3. 引言
Transformer由于缺少归纳偏置(inductive bias),常常需要大量的数据集训练,ViT论文中也提到:“Transformers do not generalize well when trained on insufficient amounts of data.”相应的,使用大规模数据集训练也要求庞大的计算资源。DeiT只是用ImageNet在一台8卡V100的机器上训练约73小时,就可以与拥有相近参数量的convnet相媲美了,而可以实现这个过程的重要结构就是知识蒸馏。知识蒸馏是Geoffrey Hinton在2014年提出的模型压缩的办法,其基本思想是使用一个效果优秀的teacher model来“教导”另一个student model,通常student model的体积比teacher model小很多,因此就达到了压缩模型的效果。
因此,这篇论文在引言的倒数第二段提出了一个问题:如何蒸馏模型呢?然后给出解答:使用专门针对Transformer的token-based策略来代替传统的蒸馏方案,即在输入端加入一个可学习的distillation token,用来重现teacher model产生的伪标签(pseudo labels)
这篇文章和MAE的论文一样,也运用了提出问题-回答问题的方式,自问自答是一种可以吸引读者阅读下去的方式,值得学习。
最后,作者从四个方面总结了DeiT的贡献:
- 不用convnet和额外的训练数据也可以在ImageNet上与SOTA模型扳扳手腕。
- 使用distillation token来做知识蒸馏,distillation token的重要性与class token相同,class token是与ground truth作比较,distillation是与教师模型输出的伪标签作比较。
- 作者在实验的过程中还发现了一个有趣的现象,用convnet教transformer比用transformer教transformer的效果要好。
- 最后,蒸馏出来的模型也可以在下游任务中表现良好。
4. 相关工作
相关工作前几段都是讲述了CNN和Transfomer的发展史,这里就不做详细讲解了。这里只讲一下最后一段有关知识蒸馏的问题。如前文所讲,知识蒸馏的作用是模型压缩,同时也可以改良由于数据增强(裁剪、旋转等)带来的标签偏差。例如:一幅图的原始分类标签为“猫”,但实际上这幅图是一幅风景图,猫只在这幅图的一个很小的角落。从分类的角度来说,这幅图的标签并没有错,因为确实有只猫,但经过数据增强之后,这幅图中含有猫的部分被裁掉了,因此原有的ground truth就产生了偏差。此时如果采用知识蒸馏的方式,teacher model很可能将增强之后不含猫的数据预测为正确的“风景”类别,这就解决了标签偏差问题。
另外,知识蒸馏还可以将CNN中原有的归纳偏置传递给Transformer模型,相较于Swin Transformer直接人为使用滑动窗口引入归纳偏置,这种传递归纳偏置的方法更加隐晦。
5. 方法
5.1 ViT
方法章节中首先对ViT进行了概述,这里对ViT的结构方面就不过多细讲了,对ViT还不熟悉的朋友可以参阅我讲ViT的博文:论文笔记-An image is worth 16x16 words: Transformers for image recognition at scale。
文章在ViT的最后一段提到了他们做fine-tune的方法,即在低分辨率的数据集上做预训练(pre-train),再在高分辨率的图像上做fine-tune,这样可以提高模型的准确性,也可以加速训练。但我们知道对于不同分辨率的图像,位置编码将不再统一,因此作者采用了跟ViT相同的方式,在做fine-tune时对位置编码进行插值来适应高分辨率图像。
5.2 Distillation through attention
本文的核心贡献之一就在此处。作者提出了两种蒸馏方式:软蒸馏(soft distillation)和硬蒸馏(hard distillation)。
软蒸馏通过最小化teacher和student model的softmax输出分布的KL散度进行知识传递,公式如下
其中第一项为student model与ground
truth计算的交叉熵损失,第二项为student model与teacher
model计算的KL散度,
也就是说,训练的目标是找到一student的输出与ground truth和teacher的输出之间的损失值之和最小。
硬蒸馏的思路更加简单,直接将teacher输出的类别当作标签,与student计算交叉熵损失,公式如下
前一项与软蒸馏基本一致,只是将loss系数设置为
对比二者我们不难发现,软蒸馏是将teacher的输出作为未知分布处理,因此使用KL散度作为目标函数,而硬蒸馏直接将teacher的输出作为标签(即当作已知分布)处理,因此可以使用交叉熵做为目标函数。KL散度与交叉熵的关系,就在于原概率分布是否已知。另外作者还提到应标签是可以转化为软标签的,具体方法来自于文献47,就是以
整个训练过程如下图所示1,图非常简单,但值得注意的是,训练的时候使用了两个输出头来做预测,再将两个分类器的softmax结果加起来计算loss。
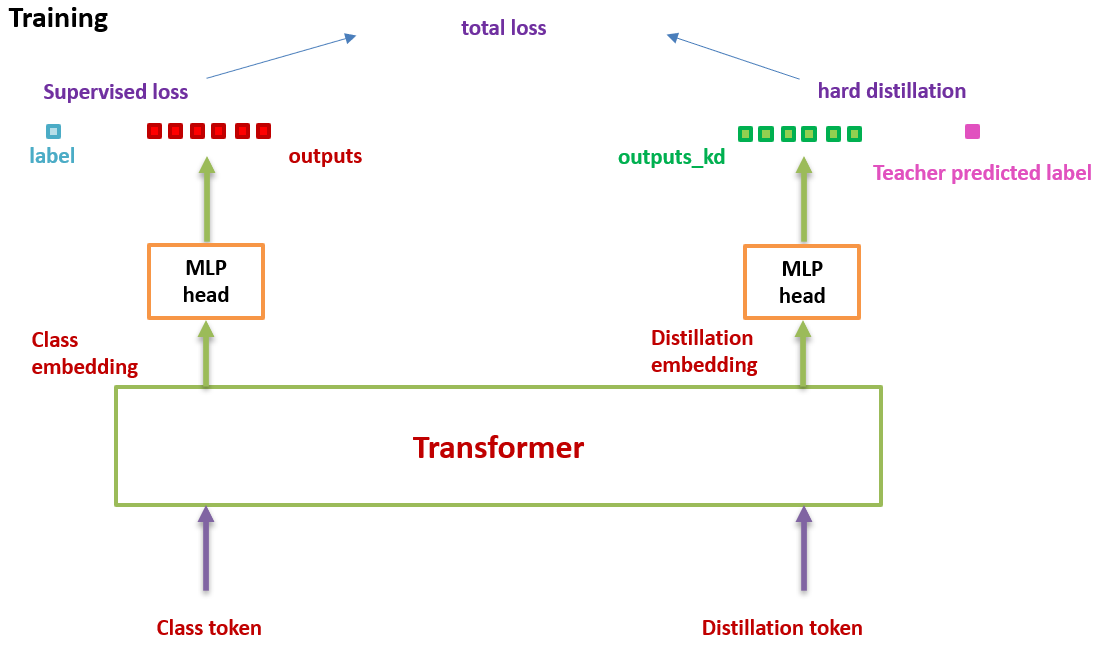
5.3 Distillation token
文章另一个核心贡献就是提出了distillation token。Distillation token的原理很简单,与class token相同,也是随机初始化一个与patch大小相同的向量,之后拼接在patch token的尾部,通过self-attention与其他patches互动,随最后一个线性层输出。该token的目标函数即为蒸馏目标中的第二项。Distillation token可以让模型从teacher中学习,与class token形成互补关系。
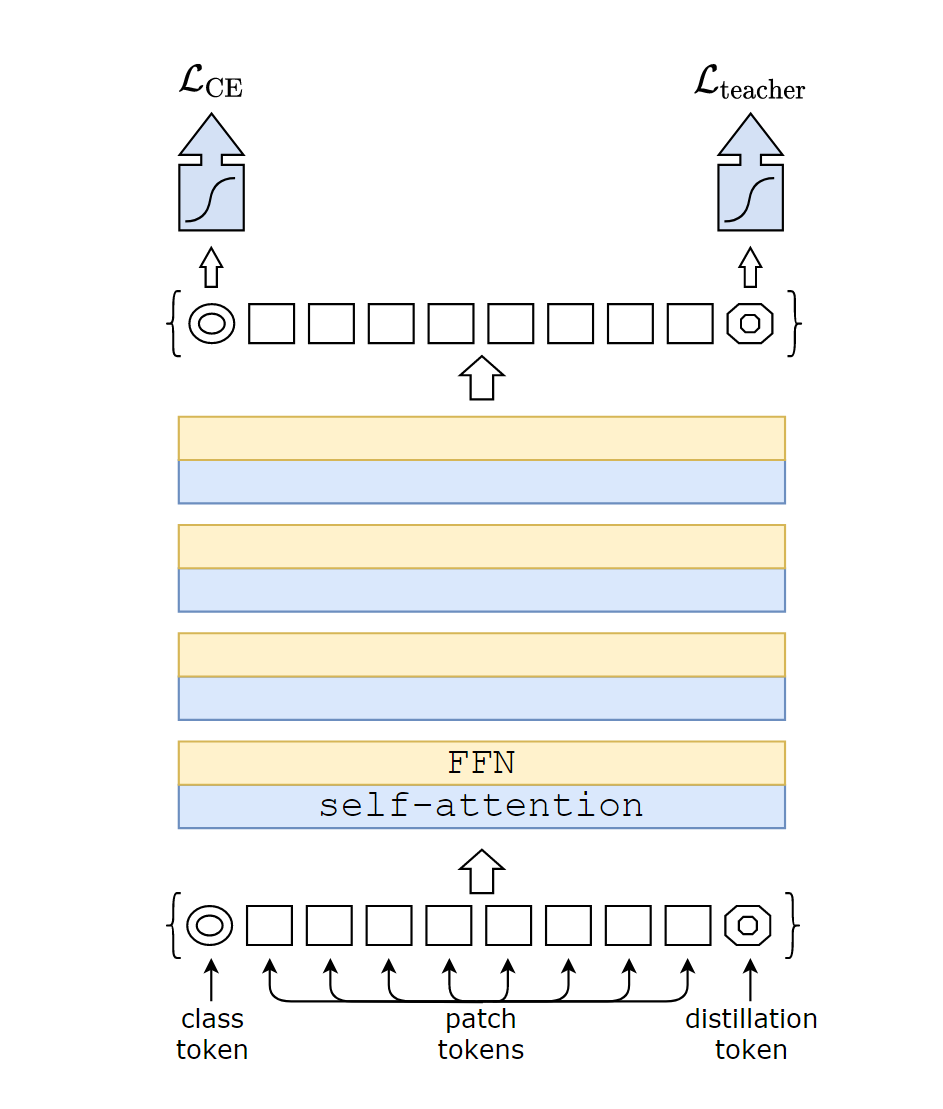
另外,作者还发现了一个有趣的现象,训练过程中,class token和distillation token是超不同方向收敛的。对每一个layer输出的两个向量计算的平均余弦相似度只有0.06,但最后一层却有0.93。也就是说,虽然最终收敛结果差不多,但收敛的过程是完全不同的。文章对此的解释是:distillation token和class token应当产生的是相近而不是相同的目标。
最后,作者证明了distillation token的确是往模型中添加了一些东西,而不是仅仅添加了一个class token。采取的方法是不用teacher输出的pseudo label,直接使用两个class tokens,结果是这两个class token朝着同一方向收敛,最终的余弦相似度为0.999。另外,增加一个class token并没有为模型带来额外的效果,对比之下,增加的distillation token是可以带来效果提升的。
6. 实验
6.1 Transformer models
作者直接采用了ViT-B作为backbone,抽头也只用了一个线性投射层,在预训练阶段称为DeiT-B,在fine-tune阶段,由于用了更大分辨率的图像,模型称为DeiT$$384。模型参数如下,其中-S和-Ti分别对应ViT的不同参数规模。

6.2 Distillation effects
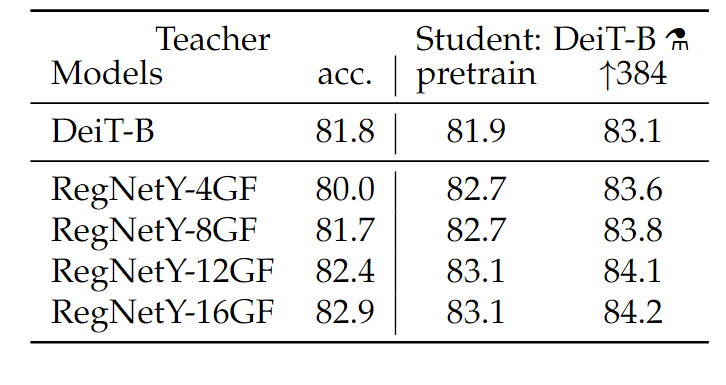
作者在实验中发现,蒸馏出来的student model居然可以比teacher model更优秀。如下图所示,使用RegNetY系列作为teacher时,student最高可以比teacher高2.7个点,这在知识蒸馏中是一件很“反常识”的事情,通常知识蒸馏在用作模型压缩时,student的效果是不如teacher的。作者对此的解释是,convnet作为teacher时,无形中可以将自己作为CNN的归纳偏置传递给student,当transformer有了归纳偏置之后,效果是比CNN要好的。
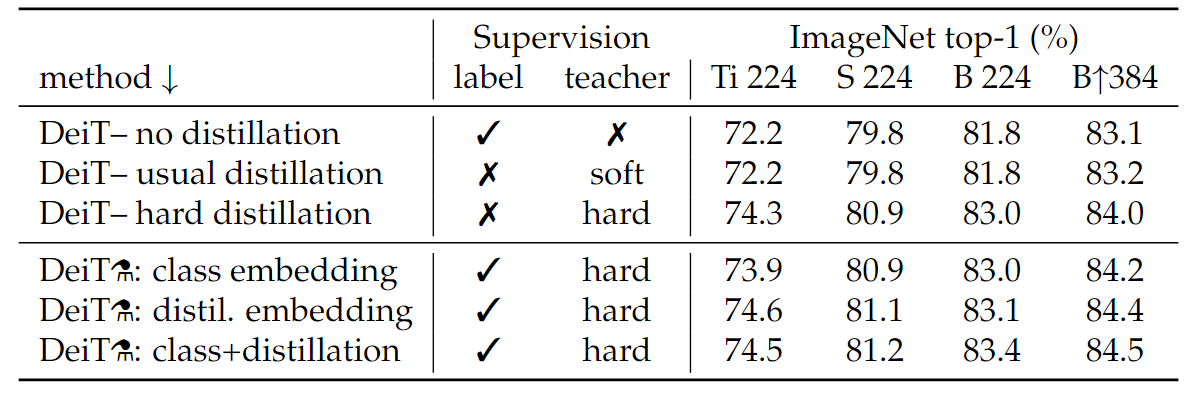
此外,作者还对比了不同蒸馏方法的结果,发现直接将teacher输出作为标签的硬蒸馏效果是最好的。
7. 结论
DeiT通过知识蒸馏的方式,使Transformer可以在更小的数据集上以更小的计算资源训练。在仅仅使用ImageNet的情况下可以达到84.2%的准确率,性能可以与当时最先进的CNN抗衡。鉴于Transformer相比于CNN晚起步了很多年,因此作者团队相信使用更少的资源训练Transformer在将来也会成为可能。
https://zhuanlan.zhihu.com/p/349315675↩︎