论文笔记-DAB-DETR:Dynamic Anchor Boxes Are Better Queryes for DETR
论文链接:https://arxiv.org/abs/2201.12329
1. 前言
自从读了DETR之后对Transformer在目标检测领域的应用觉得有些兴趣,本来想直接阅读曾经在COCO拿下SOTA的DINO的论文,但读完开头发现DINO其实是整合了前面很多创新点的方法,于是就先去读了前面几篇论文,所以接下来应该会针对DETR系列,包括Conditional DETR,Deformable DETR,DAB-DETR(本文)和DINO撰写学习笔记。
2. 摘要
由于Transformer架构本身缺少归纳偏置,需要大量的数据和实践来训练使得模型收敛。在原始的DETR中,足足训练了500个epochs才能勉强取得与Faster RCNN基线模型相同的效果。传统目标检测领域,以RCNN系列为代表,模型前向至少都是一个two-stage的过程,因此DETR这种纯端到端的学习方式立刻吸引了大批研究者跟进,DAB-DETR就是其中之一。
DAB-DETR(Dynamic anchor
boxes DETR)通过引入动态锚点框替代了原始DETR中的object
query加速模型训练收敛速度。作者认为,这是通过加入“锚点框”这一先验知识,从而改善了query和feature之间的相似性计算的结果。另外,动态锚点框也允许随时改变注意力图中锚点框的尺度,这个过程是在解码器的self-attention模块中分别对
最后,DAB-DETR在MS-COCO benchmark上取得了45.7%的AP,是当年DETR类模型中最高的。
3. 引言
引言前两段主要回顾了目标检测的历史和原始DETR的主要贡献,这里就不再赘述了。
引入作者的方法之前,我们需要知道DETR的object
queries实际上分为了两部分:decoder embeddings和learnable
queries。在原始DETR的代码中,最开始的decoder
embeddings是一组全0的向量,尺寸与learnable queries相同,而learnbale
queries是通过nn.Embedding将query数量映射到图像特征空间的一组向量。
1 | # Learnable Queries |
很多工作都认为DETR收敛慢的原因就出在learnable query上,因为原始DETR的object query是没有一丁点先验信息,学习起来当然慢了。于是后续的工作很多都是在decoder中的object query上下功夫,开始人为加入先验信息。
第三段开始开始介绍了DETR后续的改进工作。首先作者提到,大多数DETR类模型将query与一个而非多个特定的位置先验相关联,但他们具体的做法有很大的差别。例如Conditional DETR是通过基于content feature的query从而去学习一个conditional spatial query,Efficient DETR通过引入密集预测型任务来选择top-K个object queries,Anchor DETR将object queries改造成一个2D的anchor points向量。所有上述的DETR类模型都只利用了2D的位置信息,而没有考虑物体实际尺度问题。 那么如何解决尺度问题呢?只需要将原来锚点框的2D坐标信息的基础上,再添加可以随层数迭代的宽高信息即可。
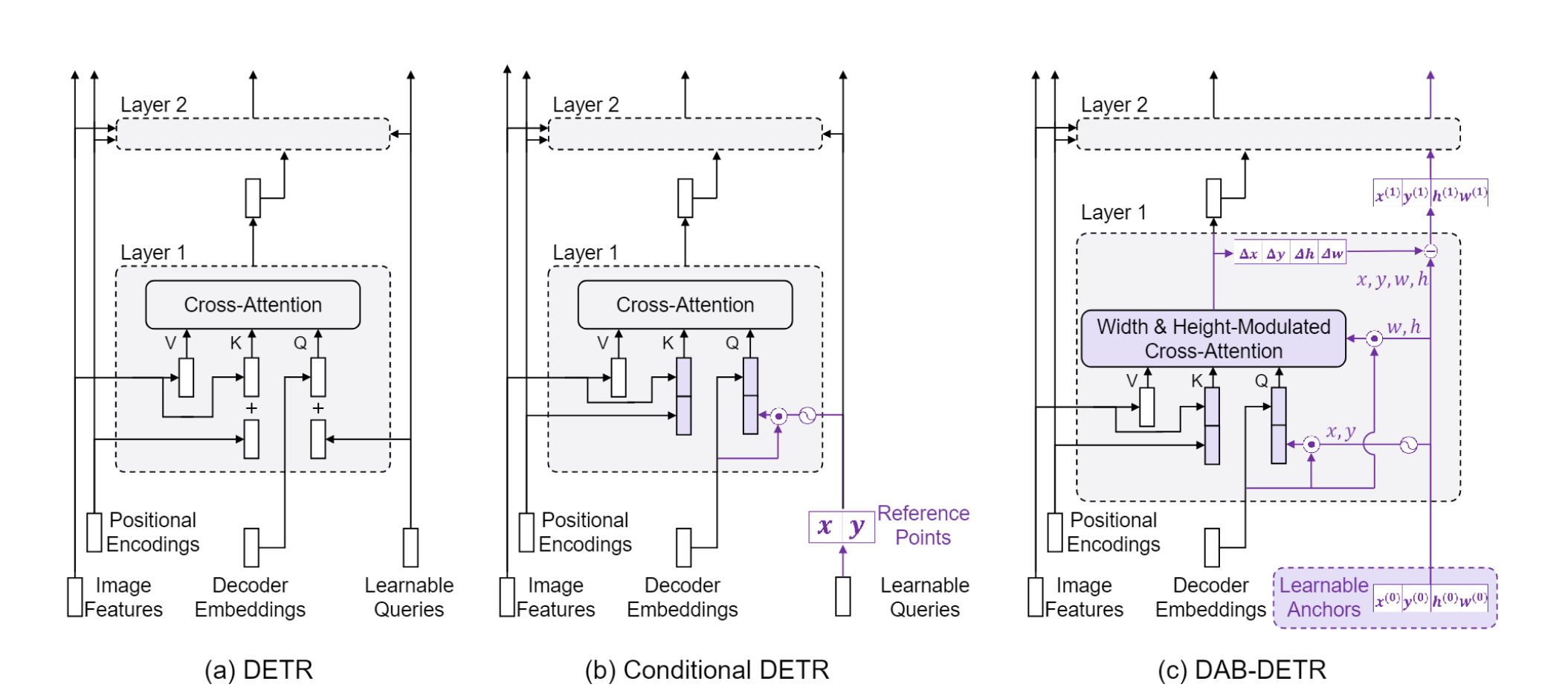
我们知道,decoder是中是将object queries(Q)与encoder中输出的特征(K,V)做cross attention,得到的输出相当于是在value矩阵中加入了object queries的信息,如果query包含了锚点框的4D坐标,就相当于将锚点框的信息注入到特征图上去了,decoder再从有先验约束的特征区域中去抽取语义,所以作者也提到,将query设计为锚点框的方法类似于Faster RCNN中的ROI pooling,称之为soft ROI pooling。
4. 为什么位置先验可以加速训练?
作者提出了两个可能导致DETR收敛缓慢的原因: - 因为优化问题导致学习object queries也很困难; - 模型学到的queries中的位置信息与encoder中使用的正弦位置编码的编码方式不同。
为了验证这两个原因,作者做了两个实验。要验证第一个原因很简单,既然推测问题出在object queries的优化过程上,那直接将训练好的object queries冻住,再去训练其他模块即可。但结果发现即使用训练好的object queries,收敛速度与重新训练object queries差不多,由此可见问题并不出在query优化上。
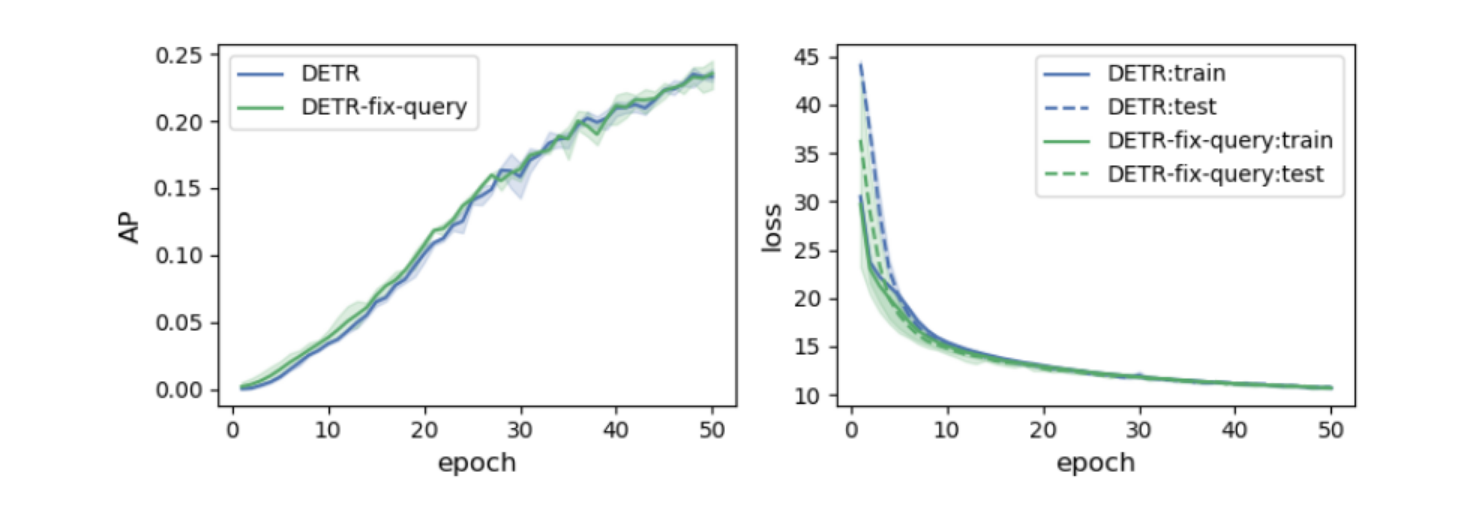
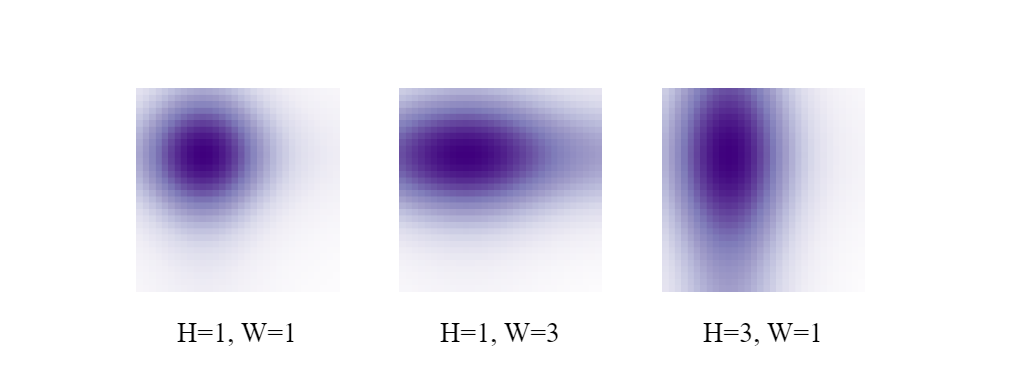
为了验证第二个原因,作者可视化了query和position key之间的注意力图。对比几张注意力图可以发现,原始DETR对于物体位置的注意力掌握的并不是很好,原文在这里所说的"multiple modes"指的是无法将注意力集中在单一的目标个体上(或者是有多个注意力中心)。而Conditional DETR和DAB DETR都可以对目标物体有一定程度的约束。Conditional DETR的query与图像原本的位置编码的编码方式是相同的,因此呈现出来的是Gaussian-like注意力图,即每个物体都是用同一尺度来界定的,从图中也能观察出每张图的注意力分布都是均匀的。DAB-DETR呈现出了更强的约束性,不同物体的不同尺度(宽,高)都被清晰地展现出来,这一结果就来自于用anchor的宽高信息调整了attention的计算方式,这一点将在后文中讲到。

于是作者团队就下结论说:query学习到的multiple modes或许就是导致DETR训练缓慢的根本原因。因为原始DETR的query实在是缺少先验信息,因此我们有理由相信,引入位置先验来约束query的位置是可行的。最后作者说明除了query,其他模块都是与原始DETR相同,保证实验的严谨性。
5. DAB-DETR
既然要引入位置先验来加速训练,那么在目标检测领域,anchor box一定是最好的先验信息了。不论是Faster RCNN系列还是其他传统目标检测的two-stage模型,都是先往图上打anchors,再通过非极大值抑制(NMS)来去除多余的框。DAB-DETR也采用了类似的思路,不过这里的anchors被设置为了可学习的向量,每一个物体对应只出一个框,而不是像Faster RCNN一开始预先定义好的9个框,因此最后也不需要NMS了。
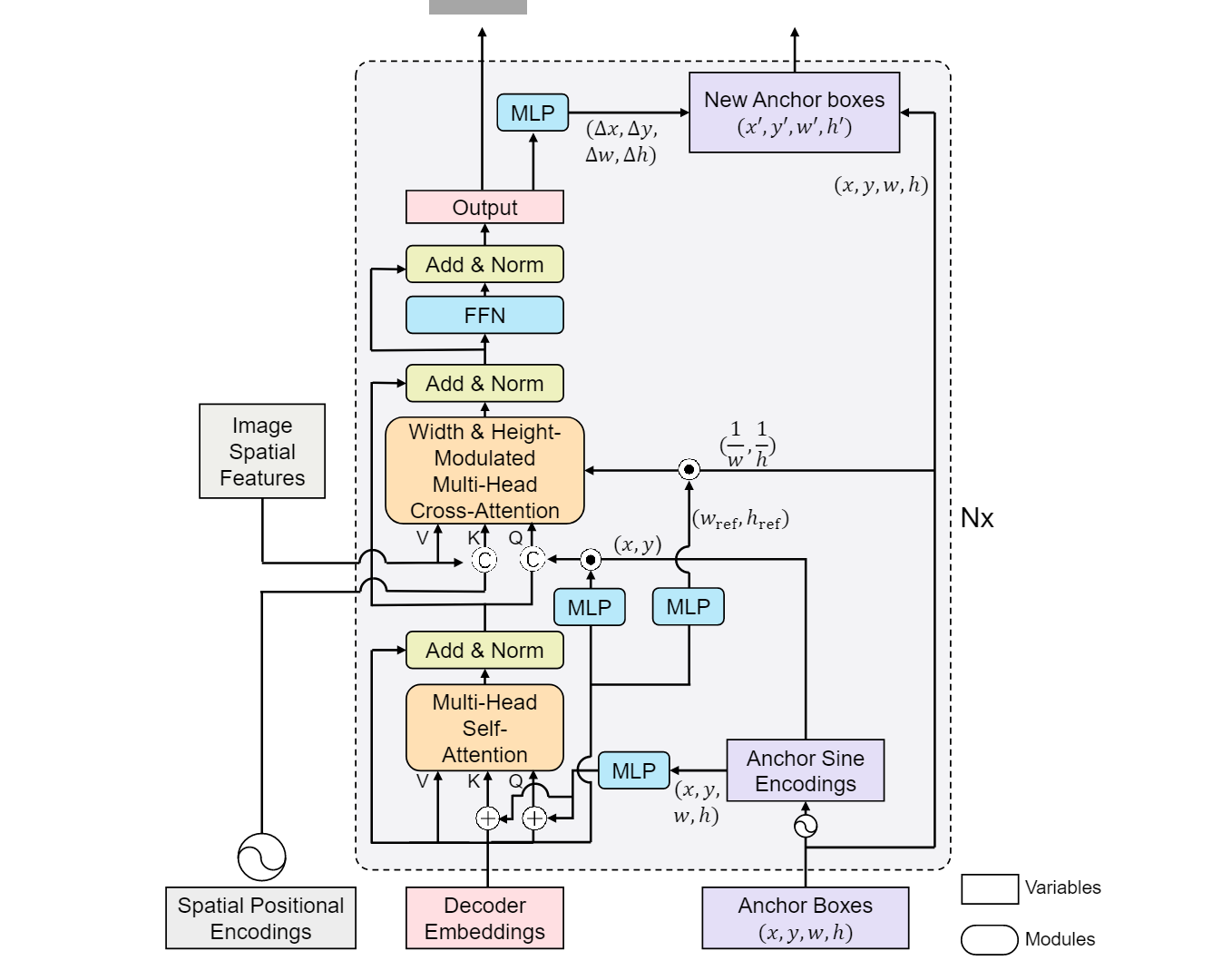
先来看一下DAB-DETR的整体模型架构,因为这个工作主要是对decoder进行重新设计,encoder与原始DETR一样,所以文章中也只给出了decoder的结构图。总体来说,DAB-DETR decoder由一个self-attention和一个cross-attention模块组成。
5.1 Self-attention
我们首先看self-attention模块。self-attention模块的输入是由decoder embeddings和anchor boxes(也就是改进后的learnable queries)组成。从DAB-DETR的代码中我们可以知道第一层中decoder embeddings是一组维度与encoder图像特征相同的值为0的向量,这样做的目的是为了之后能在cross-attention模块中直接与图像特征进行交互,因为不论什么attention模块都是不改变矩阵维度和尺寸的。Anchor boxes则首先经过一次正弦编码,再通过一个MLP层映射到与decoder embeddings相同的维度后与decoder embeddings相加。此处的正弦编码方式与Attention is all you need一文中的位置编码很相似,唯一的区别是加入了温度系数来控制attention map的分布,公式细节将在后文中讲到。
接下来结合文章中的公式来对self-attention做数学上的讲解。假设第
PE即为正弦位置编码,实际上,anchor的正弦位置编码是分别对
总的来说self-attention模块比较简单,就是将原始DETR中的learnable queries做了替换。
5.2 Width & height-modulated multi-head cross-attention
Cross-attention模块,全称为width & height-modulated multi-head cross-attention,实际上就是用anchor的宽高信息对attention的输入进行调整。
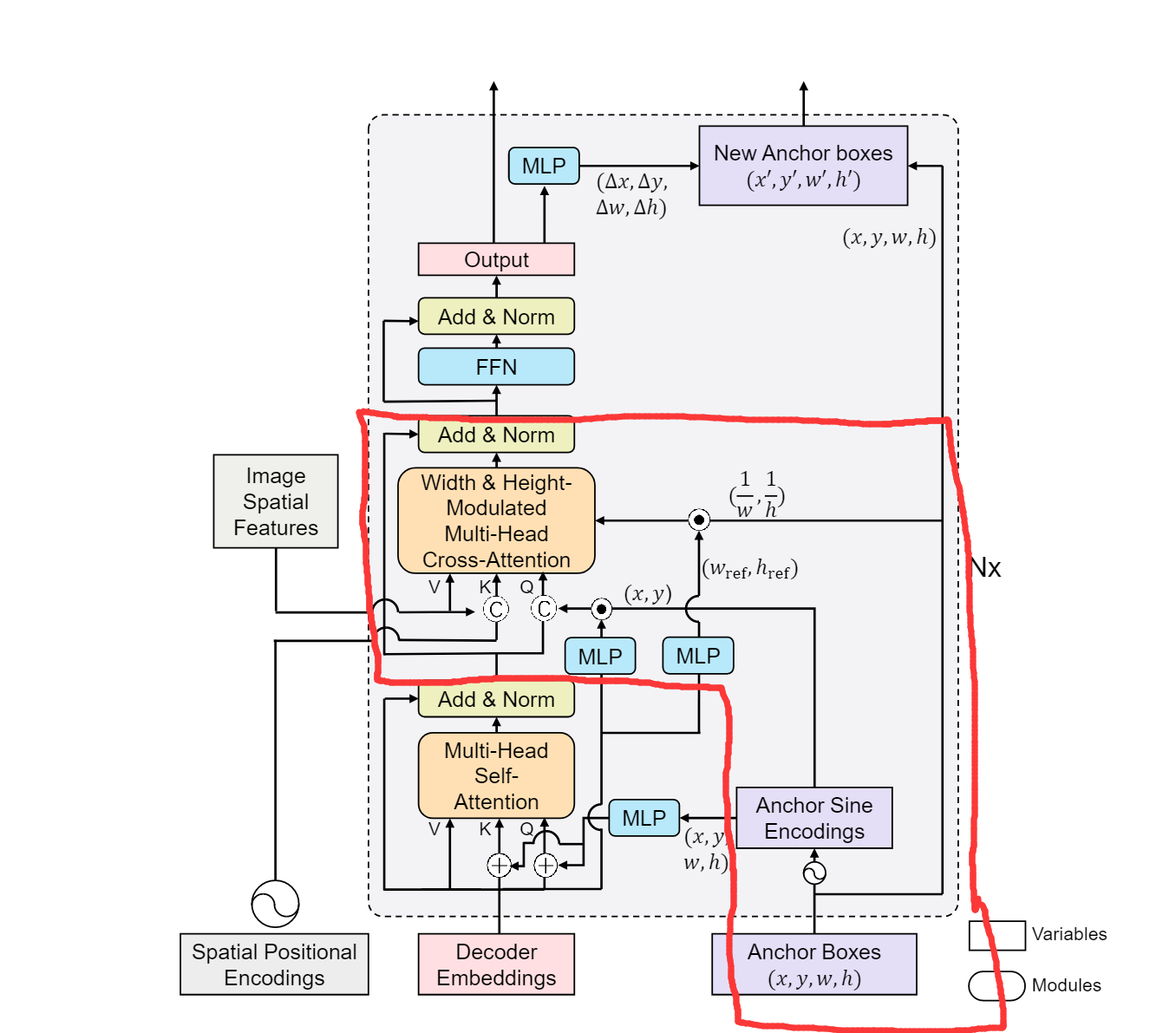
首先我们要明白,cross-attention的作用是将尺度信息映射到原图像特征当中去。在cross-attention中,原始图像的特征和位置编码被用作K和V的输入,而self-attention层的输出与经过MLP调整维度后的decoder
embeddings以及经过正弦编码的anchor进行点积运算,然后将结果拼接起来作为Q输入。
这里有一个问题,为什么要将decoder
embeddings和anchor的点积运算作为positional embedding?1
答:因为从输出端看,decoder embedding是要用来算anchor的偏移量
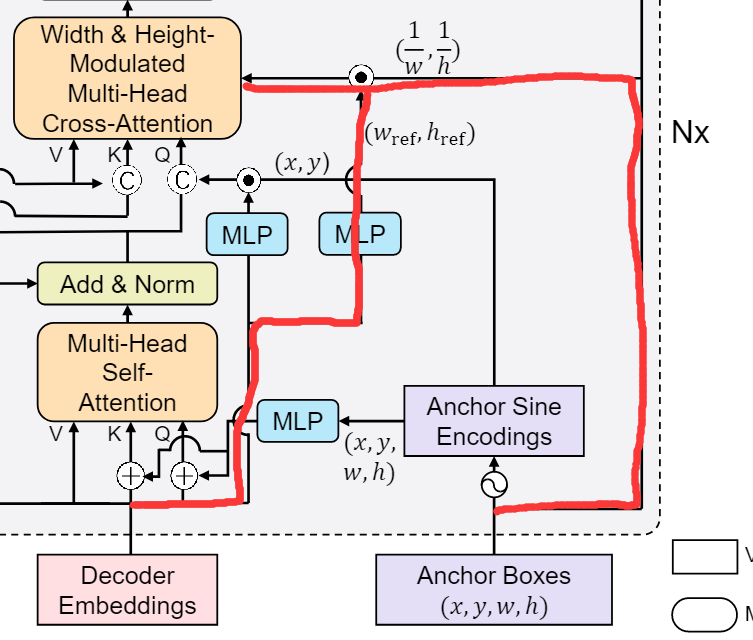
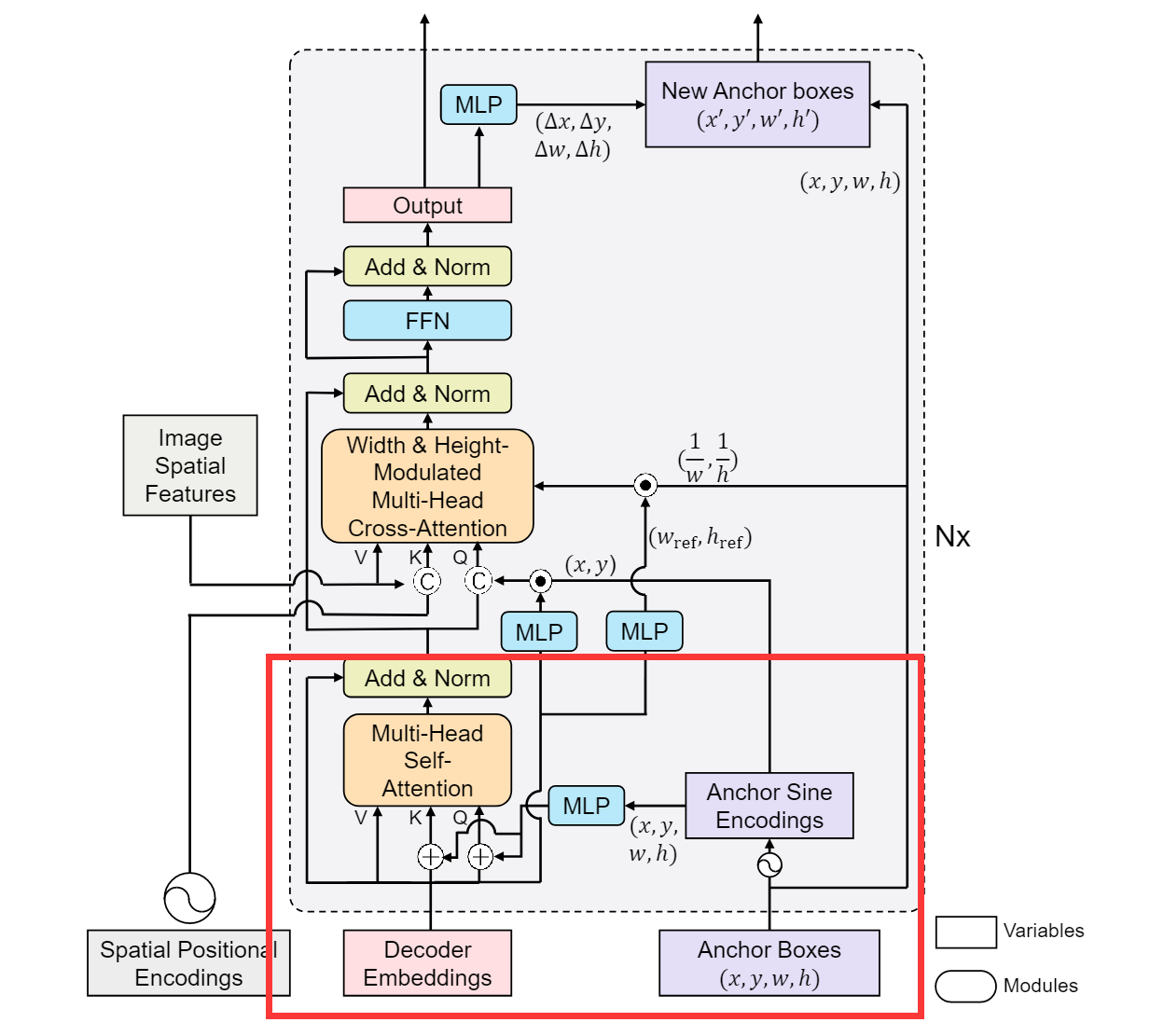
最后来看一下这条红线标注的路径,这条路径并不代表任何输入或者输出,它代表的是计算modulated
cross-attention的方式。假如没有这两条红线,那么将尺度信息加入到图像特征就是分别对
改进后的cross-attention分别在
其中
其中
5.3 Temperature tuning
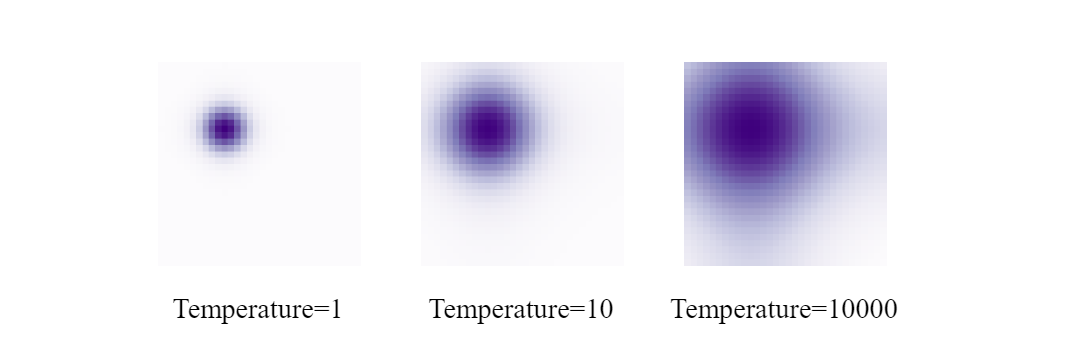
在self-attention模块中作者对原始的正弦编码做了改进,加入了温度系数来调节位置先验的尺寸,直观来说,温度越高,尺寸越大。改进后的公式如下
注意在本文的任务中,
6. 结论
DAB-DETR的主要贡献就是通过引入dynamic anchor boxes这一位置先验来加速模型训练,这个操作类似于级联式的ROI pooling。DAB-DETR也给了我们启发:除了anchor以外还有其他改进query的方法吗?