1. 二分搜索
二分搜索的核心思想是把一个有序数组 分为两部分,然后判断值在哪一部分,然后再在那一部分中进行二分搜索,直到找到目标值。
代码:循环版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> using namespace std;int binary_search (int arr[], int x, int n) int main (void ) int arr[9 ] = {1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 }; int x = 5 ; int n = 9 ; int pos = binary_search (arr, x, n); cout << pos << endl; } int binary_search (int arr[], int x, int n) int left = 0 ; int right = n-1 ; int mid = 0 ; while (left < right){ mid = (int )((left-right)/2 ) if (arr[mid] == x) return mid; if (arr[mid] > x){ right = mid+1 ; } if (arr[mid] < x){ left = mid-1 ; } } return -1 ; }
代码:递归版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> using namespace std;int recursive_binary_search (int arr[], int left, int right, int x) int main (void ) int arr[9 ] = {1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 }; int x = 5 ; int n = 9 ; int pos = binary_search (arr, x, n); cout << pos << endl; } int recursive_binary_search (int arr[], int left, int right, int x) int mid = (int )((left-right)/2 ); if (left > right) return -1 ; if (arr[mid] == x) return mid; if (arr[mid] > x){ recursive_binary_search (arr, left, mid-1 , x); } if (arr[mid] < x){ recursive_binary_search (arr, right, mid+1 , x); } }
2. 排序/时间复杂度
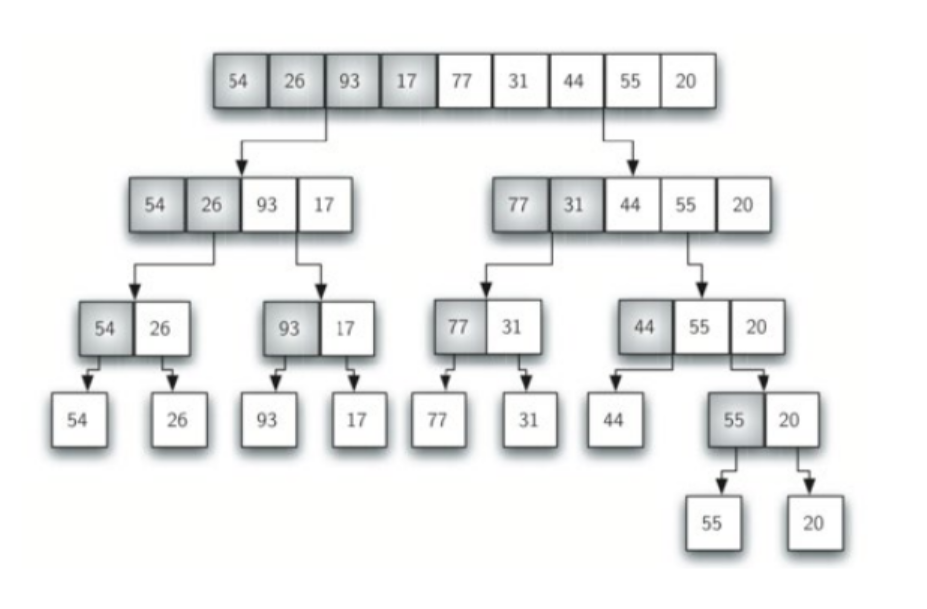
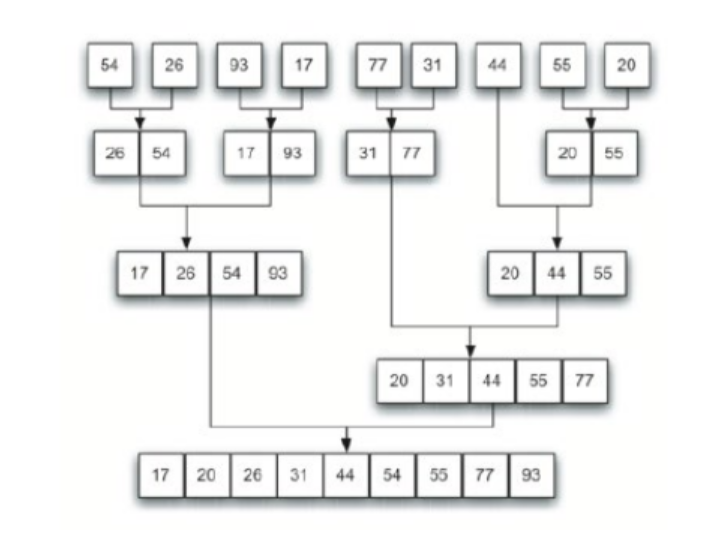
2.1 合并排序
合并排序的步骤有:
分解(Divide):将原数组通过二分法分为最小的单位数组;
解决(Conquer):用合并排序法对两个子序列递归地求解排序;
合并(Combine):合并两个已排序的子序列以得到排序结果。
分解过程
合并过程
说这么多不如直接看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <iostream> using namespace std;void Merge_sort (int arr[], int left, int right) void Merge (int arr[], int left, int mid, int right) int main (void ) int arr[12 ] = {3 ,4 ,1 ,6 ,1 ,3 ,5 ,8 ,12 ,5 ,5 ,12 }; for (int i = 0 ; i < 12 ; i++){ cout << arr[i] << " " ; } cout << endl; Merge_sort (arr, 0 , 11 ); for (int i = 0 ; i < 12 ; i++){ cout << arr[i] << " " ; } } void Merge_sort (int arr[], int left, int right) if (left < right){ int mid; mid = (int )((left+right)/2 ); Merge_sort (arr, left, mid); Merge_sort (arr, mid+1 , right); Merge (arr, left, mid, right); } } void Merge (int arr[], int left, int mid, int right) int * B = new int [right - left + 1 ]; int i = left; int j = mid + 1 ; int k = 0 ; while (i <= mid && j <= right){ if (arr[i] <= arr[j]){ B[k++] = arr[i++]; } else { B[k++] = arr[j++]; } } while (i <= mid){ B[k++] = arr[i++]; } while (j <= right){ B[k++] = arr[j++]; } for (i = left, k = 0 ; i <= right; i++){ arr[i] = B[k++]; } delete [] B; }
2.2 时间复杂度
简而言之,计算时间复杂度就是计算代码执行次数的最高次项。考试要求的是给出伪代码计算时间复杂度。
以合并排序为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 MERGE(A,p ,q ,r ) n1=q-p+1 ; n2=r-q; create new arrays L[n1 +1 ] and R[n2 +1 ] for i=0 to n1-1 L[i ] =A[p +i ] for j=0 to n2-1 R[j ] =A[q +1 +j ] L[n1 ] =99999 R[n2 ] =99999 i=j=0 for k=p to r if (L[i ] <=R[j ] ) A[k ] =L[i ] i=i+1 else A[k ] =R[j ] j=j+1 MERGE_SORT(A,p ,r ) if p<r q=floor((p+r)/2 ) MERGE_SORT(A,p ,q ) MERGE_SORT(A,q +1,r ) MERGE(A,p ,q ,r )
函数MERGE的时间复杂度是
再比如插入排序的伪代码,因为for循环中套了一个while循环,复杂度上限为
1 2 3 4 5 6 7 for j =2 to A.length key =A[j] i =j-1; while i>0 and A[i]>key A[i+1]=A[i] i =i-1 A[i+1]=key
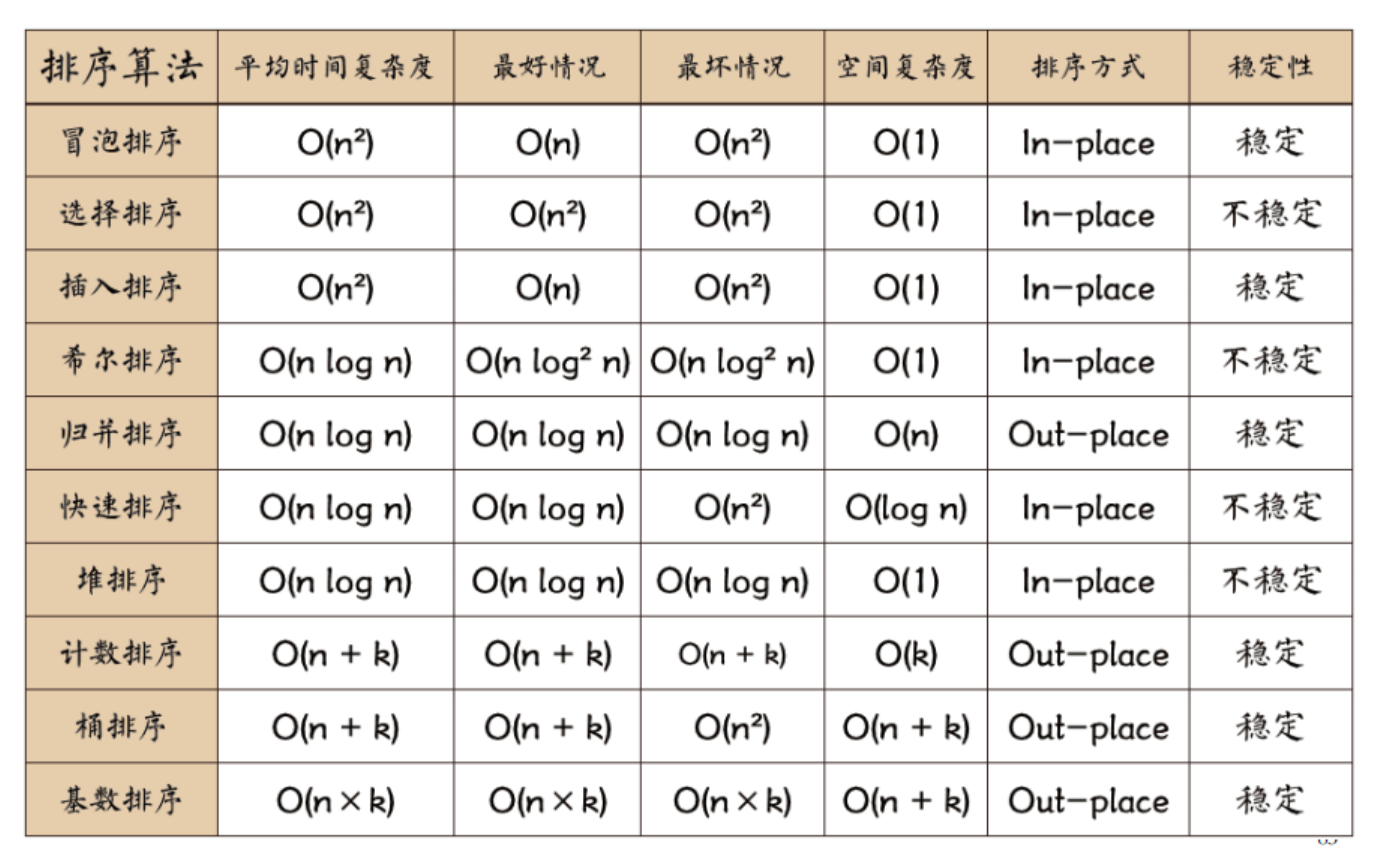
考试复杂度多半从各大排序算法中出题,背一背这张表应该会有用。一个准则就是,一看就很简单能快速算出来的,多半是
3. 动态规划
3.1 概念
动态规划(Dynamic Programming,
DP)的基本思想是将待求问题分解为若干子问题,每个子问题不是相互独立的 ,用分治法求解时有些子问题会被重复计算很多次。DP则采用一个数组的形式储存已经计算过的子问题,在接下来再次遇到该问题时直接查表解决。
考试伪代码多半从排序算法里出,背一背这张表应该比较有用
DP与分治法的异同
相同点
不同点
DP与分治法都是将目标问题分解为若干子问题,先求解子问题,然后从子问题中求解原问题
DP分解出来的子问题往往不是独立的,如果用分治法求解,则很多子问题会被重复计算
3.2 矩阵连乘加括号问题
直接看例子
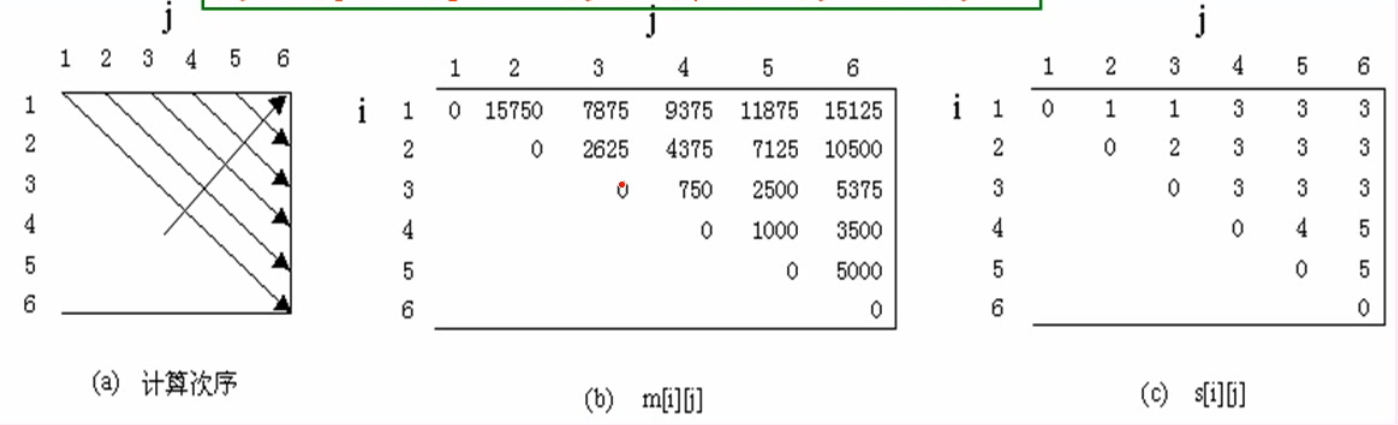
6个矩阵连乘
考试请牢记 ,第
其中
如图所示,从矩阵主对角线开始计算,主对角线元素全为0,因为只有一个矩阵,没有乘法。次对角线为相邻两个矩阵相乘的代价,直接计算即可。其余的对角线则需要按照上面提到的公式计算。例如
显然
如何从
从右括号 应该加在
为了美观,整理一下就有
4. 遗传算法
遗传算法只考概念和流程
遗传算法是一种基于自然群体遗传进化机制的自适应全局优化概率搜索算法。
遗传算法有三个关键步骤 :
遗传算法的基本机理:适应度函数 。
适应度函数决定了染色体的优劣程度,对于优化问题,适应度函数就是目标函数。
4.1 选择
选择也称赋值操作,根据个体的适应度函数值度量决定该解是否可以遗传到下一代。
主要思想:适应度值交大的染色体有交大的选择(复制)机会
P.S. 个人感觉这里用softmax感觉会更合理
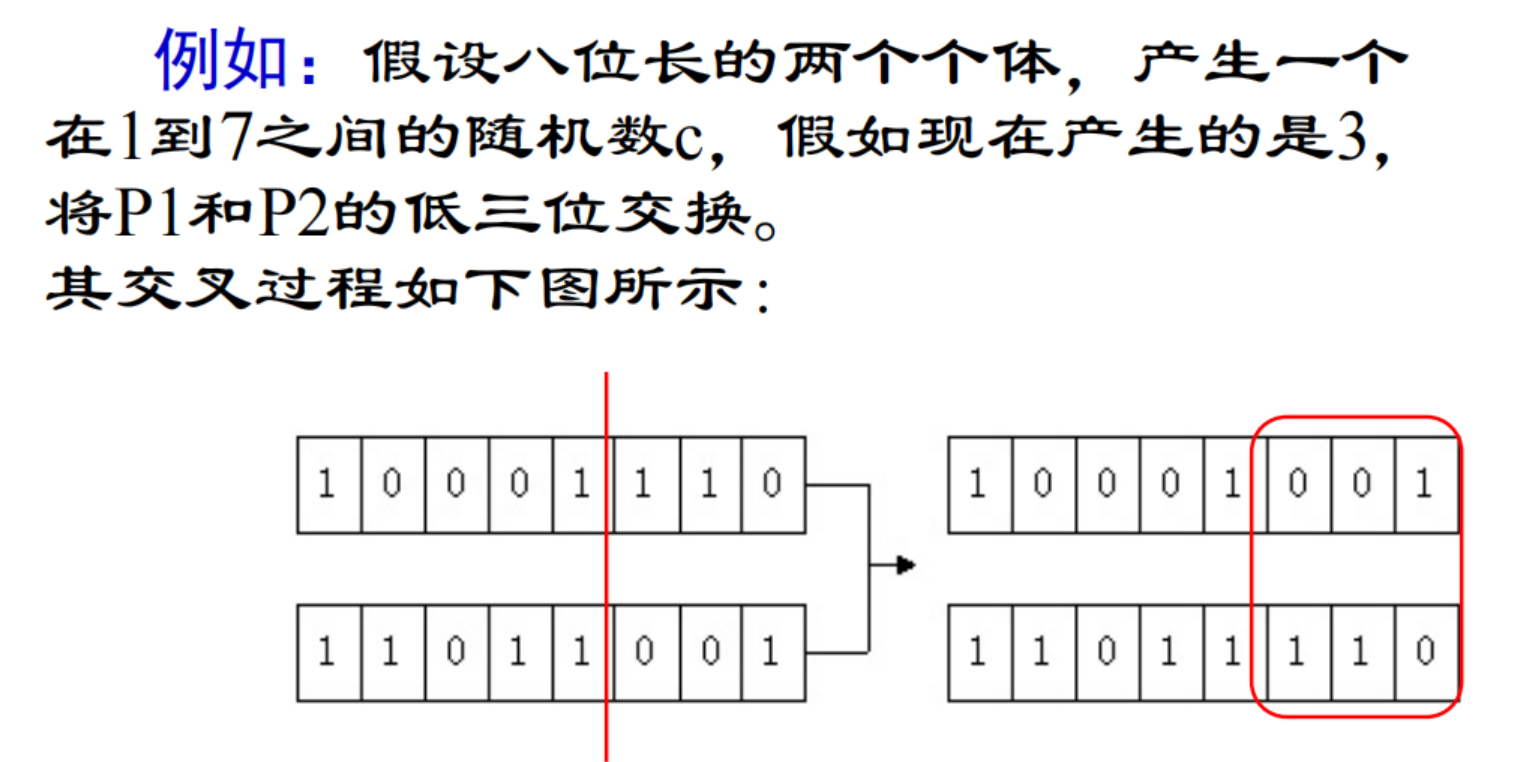
4.2 交叉
将被选择出来的两个个体作为父母个体,将二者部分码值进行交换,这个交换要求产生一个随机数
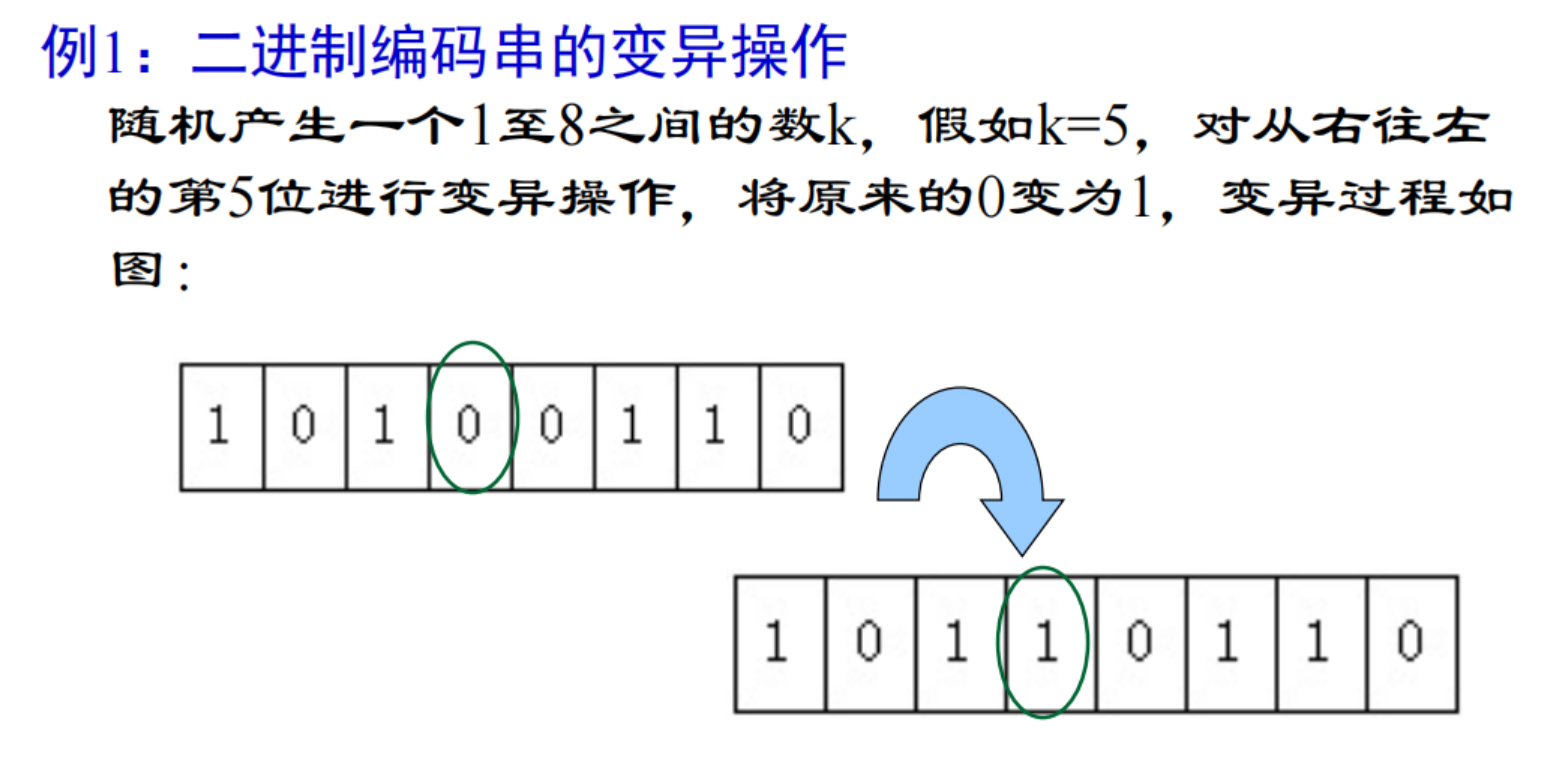
4.3 变异
随即改变数码串上某个位置的数字
5. 粒子群算法
5.1 PSO的基本思想
每个寻优的问题解称为“粒子”。所有粒子都在一个D维空间进行搜索。所有的粒子都由一个fitness
function
确定适应值以判断目前的位置好坏。每一个粒子必须赋予记忆功能,能记住所搜寻到的最佳位置。每一个粒子还有一个速度以决定飞行的距离和方向。这个速度根据它本身的飞行经验以及同伴的飞行经验进行动态调整。
5.2 PSO公式
假设D维空间中有N个粒子,每个粒子有如下参数
粒子位置:
例子速度:
粒子个体经历过的最好位置:
种群经历过的最好位置:
通常,位置和速度都有他们自己的变化范围
PSO的核心公式 :粒子
参数解释:
参数
含义
第
第
加速度常数,调节学习最大步长
两个随即常数,取值范围
惯性权重,非负数,即对前一个状态的依赖程度
理解记忆:PSO速度更新公式有三部分
递推部分:粒子上一个状态的速度加权
认知部分:当前粒子自身的思考,可理解为粒子
社会部分:可理解为粒子
5.3 PSO的参数影响
参数
影响
失去对粒子本身速度的记忆
“只有社会,没有自己”,所有位置更新取决于群体位置,容易陷入局部最优无法跳出
“只有自己,没有社会”,所有位置更新取决于自己位置,没有信息共享,导致算法收敛速度变慢
5.4 全局PSO与局部PSO
全局PSO是指每次更新都使用一个群体内所有粒子的位置信息,局部PSO是指只将群体中的部分个体作为粒子的邻域。类似于Batch
SGD和mini-Batch SGD的关系。
二者优缺点:
全局收敛快,但容易陷入局部最优
局部收敛慢,但很难陷入局部最优
5.5 粒子群算法流程
在初始化范围内,对粒子群进行随机初始化,包括随机位置和速度
计算每个粒子的适应值
更新粒子个体的历史最优位置
更新粒子群体的离职最有位置
更新粒子的速度和位置,公式如5.2所示
若未达到终止条件,则跳转第二步
6. 决策树
详情见我写的另一篇笔记 ,这里只针对考点做总结。
6.1 信息增益
要算信息增益需要先算条件熵
把
信息增益计算为信息熵减去条件熵。
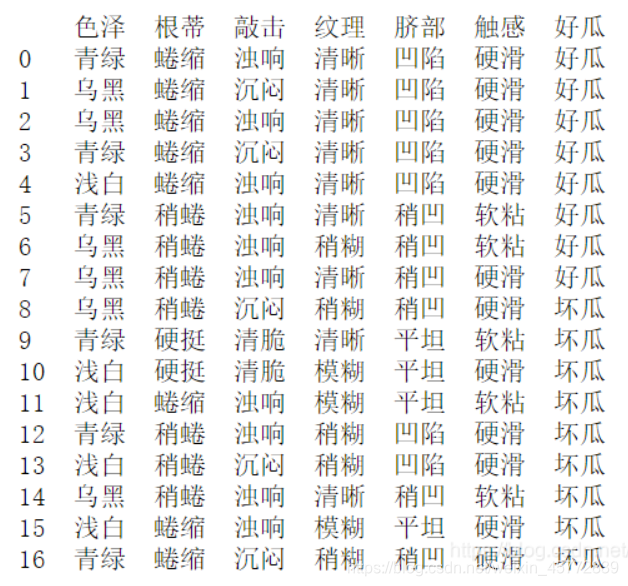
直接看例子
下图是西瓜数据集,考试也从这个里面出题
最终目的是要区分好瓜坏瓜,所以随即变量好 瓜 坏 瓜
要计算信息增益则还需要计算每个属性的条件熵,以色泽为例,色泽为青绿的瓜有6个,其中好瓜3个,则令色泽青绿为
这里
同理可得色泽乌黑(
根据信息增益定义式有
6.2 预剪枝与后剪枝
剪枝(pruning)的目的是为了避免决策树模型过拟合。
预剪枝:指在构造决策树的过程中,先对每个节点在划分前进行估计,若当前的节点划分不能带来决策树模型的泛化能力提升,则不对当前节点进行划分并且将当前节点标记为叶节点。
后剪枝:指先把决策树构造完毕,然后自底向上地对非叶节点进行考察,若将该节点对应的子树换位叶节点能带来泛化性能地提升,则把该子树替换为叶节点。
7. 聚类
聚类只考K-means聚类
K-means聚类的度量指标是L2距离
K-means聚类的基本步骤为:
随机选择
计算每个样本
根据距离将
划分好之后对每个簇内求平均,重新计算新的均值向量
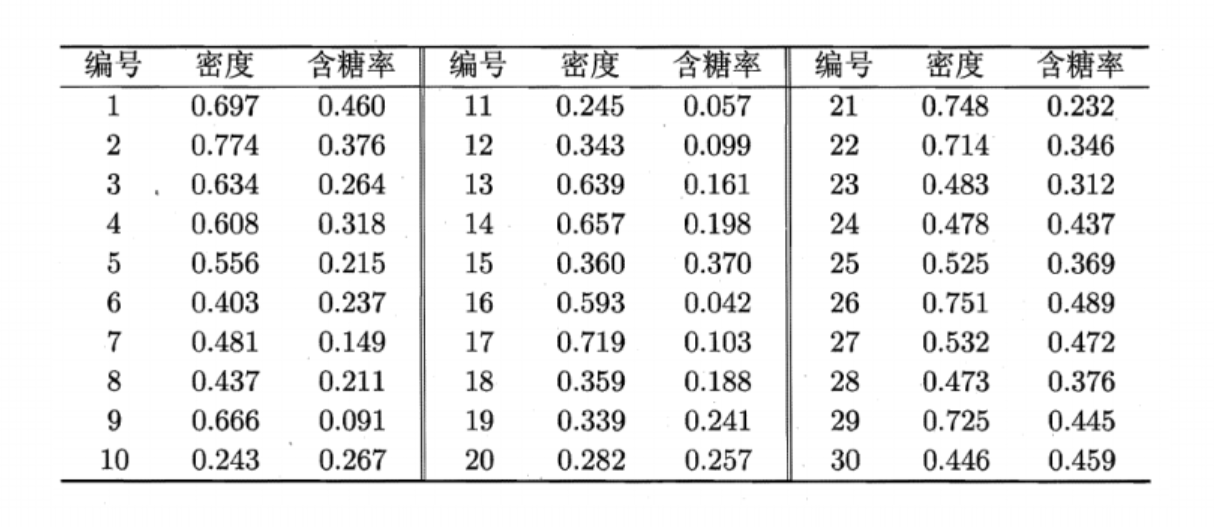
直接看例子
假定聚类数
考察样本
'_' allowed only in math mode \begin{aligned} &C_{1} =\{\boldsymbol{x}_5,\boldsymbol{x}_6,\boldsymbol{x}_7,\boldsymbol{x}_8,\boldsymbol{x}_9,\boldsymbol{x}_{10},\boldsymbol{x}_{13},\boldsymbol{x}_{14},\boldsymbol{x}_{15},\boldsymbol{x}_{17},\boldsymbol{x}_{18},\boldsymbol{x}_{19},\boldsymbol{x}_{20},\boldsymbol{x}_{23}\} \\ &C_2=\{\boldsymbol{x}_{11},\boldsymbol{x}_{12},\boldsymbol{x}_{16}\} \\ &\text{C_3} =\{\boldsymbol{x}_1,\boldsymbol{x}_2,\boldsymbol{x}_3,\boldsymbol{x}_4,\boldsymbol{x}_{21},\boldsymbol{x}_{22},\boldsymbol{x}_{24},\boldsymbol{x}_{25},\boldsymbol{x}_{26},\boldsymbol{x}_{27},\boldsymbol{x}_{28},\boldsymbol{x}_{29},\boldsymbol{x}_{30}\} \end{aligned}
然后对
如此循环往复,直到终止条件。