随机信号处理笔记-第五章:功率谱估计
1. 谱估计的定义
谱估计的定义:确定信号在特定频率(或频带)处的功率含量
另外回顾一下第一章的内容,随机信号过线性系统输入与输出的功率谱关系为
2. 无偏估计、最小方差估计和一致估计
假设
| 估计 | 定义 |
|---|---|
| 无偏估计 | |
| 最小方差估计 | |
| 一致估计 | 当数据量 |
无偏估计的作用是让估计数据分布在目标数据中心的周围,最小方差估计的作用是让估计数据尽可能近的分布在同一区域。一致估计则是让估计数据与尽可能以一个小的范围(最小方差)分布在目标数据中心(无偏)附近。
3. 经典谱估计方法
谱估计方法很多,这里暂时只记录老师提到的重点内容周期图法
3.1 周期图法
3.1.1 周期图法的步骤
设一个长度为
则该信号的周期图定义为:
周期图法就是让估计的功率谱等于周期图
放在一起对比一下原来的功率谱
可以看出周期图法其实就是用一部分有限长功率谱替代无限长的信号的功率谱
3.1.2 验证周期图法的无偏性
接下来验证一下周期图法的无偏性
令
我们知道
很显然
周期图法不满足无偏性
实际上这个
3.1.3 周期图法的频域特性
接下来把
把3.1.2中最终得到的
两个门函数的分别在
带入
这就是一个辛格函数的形式
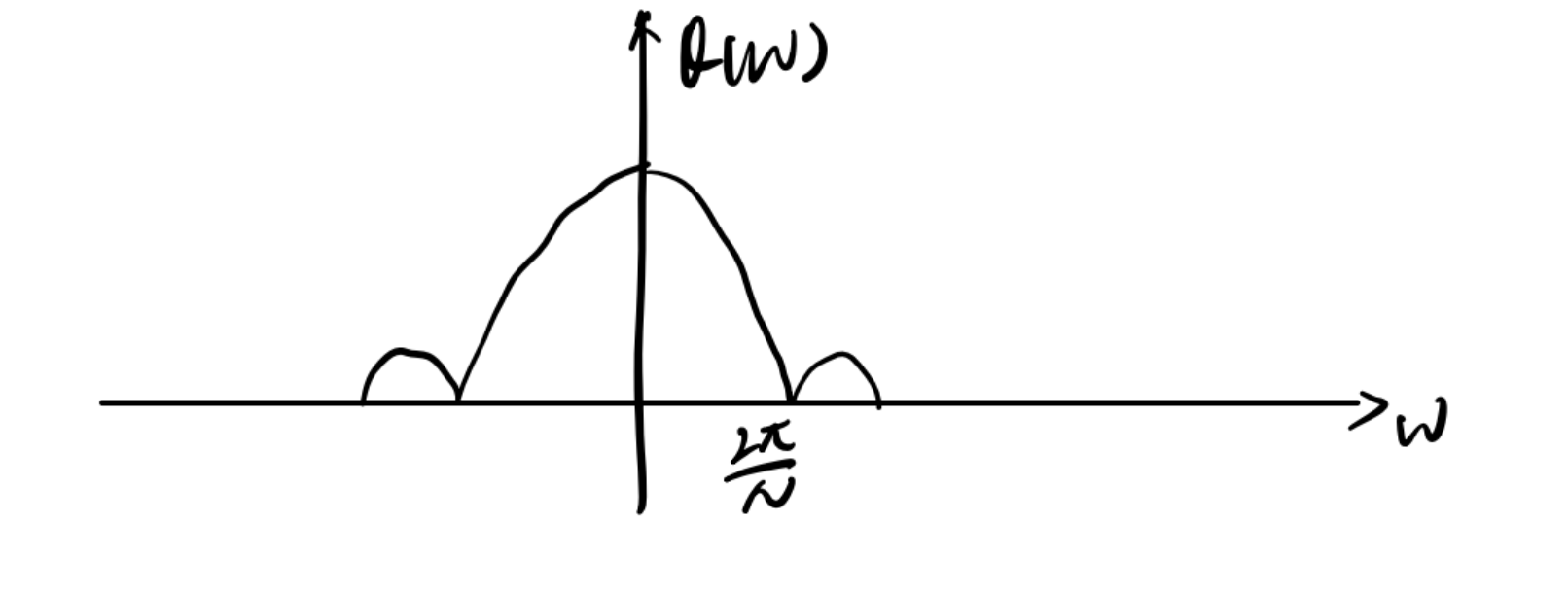
也就是说,周期图法相当于在频域上用辛格函数与原信号的功率谱做卷积。
3.1.4 验证周期图法的方差
周期图法验证方差比较复杂,但周期图与原来的方差存在以下关系
显然
结合3.1.2中的结论,周期图法不是一致估计。
3.2 谱分辨率
3.1.2和3.1.3节中说明了周期图法实际上就是相当于时域上对自相关函数加窗,频域上用辛格函数与原功率谱卷积。但是直接加窗很显然会带来影响,比如频谱泄露、混叠等等,这里主要分析混叠的影响。
例如,当
因此,主瓣宽度就决定了谱分辨率的大小,而同等采样速率条件下,主瓣宽度又取决于信号长度
频域分辨率取决于观测时间
时域分辨率取决于信号带宽
结合周期图法本身的特点,可以总结出周期图法存在的两个问题
- 小信号的主瓣可能被大信号的旁瓣淹没
- 数据短(
较小)的时候频率谱分辨率较低
3.3 降低谱估计方差的方法
降低方差最直接的方式就是求平均。
例如,假设有
周期图法降低方差的思想则是将序列分为若干段,每一段分别用周期图法估计,最后将每一段的谱估计求平均。例如,将长度为
那么第
需要注意的是,在选择
最后,将这
如果满足各段数据不想关的条件,则最后估计的方差只有原来的
但是,当
4. 参数化模型谱估计方法
参数化模型谱估计是指通过参数估计的形式直接将滤波器系数估计出来。用第二章维纳滤波的白化滤波器作为例子,假设一个信号
回忆本章第一节中提到输出功率谱与输入功率谱之间的关系,这里输入为白噪声:
现在的任务就是通过一些方法对
实际上这些都是时间序列分析中常用的模型,还有一个ARIMA模型,是对ARMA模型的改进。
这门课重点是AR模型,MA,ARMA等可以自行了解下,这部分与数学建模有交叉,还是很有趣的。
4.1 AR模型
4.1.1 AR模型求解方法
AR(Auto regressive)模型在信号处理中的一大特点就是
既然没有分子项,那么AR模型的滤波器以及输出信号功率谱应当具备以下形式(考试要会辨认)
根据信号与系统的知识,由滤波器
这个式子是
另外不要忘了,根据滤波器的形式
为了防止混淆,这里列一个表方便对比
| 形式 | 表达式 |
|---|---|
| 递推式 | |
| 滤波器式 |
同样,可以写出
等式右边第二项,当只考虑
特别的,当
理解起来也很简单,就是输出与输入互相关函数。由于系统是因果的,未来的输入肯定与当前输出没关系。而输出
由于
将
写为矩阵的形式就有
这个矩阵方程就是第二章中一步预测的Yule-Walker方程,因此求解系数
最后简单看一下AR模型的误差,这里仅需记住两个结论:
- 预测阶数在AR模型阶数范围内时,误差随预测阶数的增加而减少,但低阶AR模型做高阶预测时,误差将不再减小。比如一个二阶AR模型,做一阶预测(即只使用
做预测)的误差比使用二阶预测的误差大,但如果三阶预测的时候,误差就不会再减小了。 - AR模型的阶次越大,使用的预测阶数越多,误差越小,预测的越准,但误差是有下限的,这个下限与输出功率谱有关。
4.1.2 AR模型的逼近
对一般的随机信号
首先对
则它与
现在假设有一个滤波器
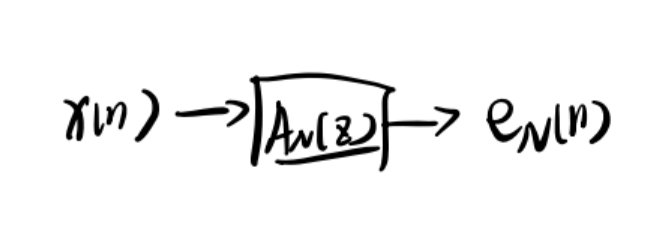
反过来将
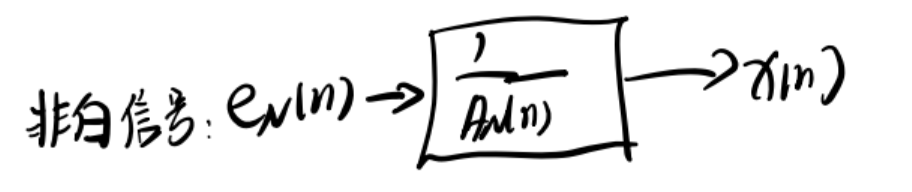
用AR模型逼近时,用方差为
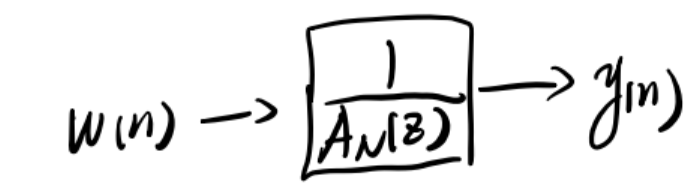
该逼近隐含了一个条件:
4.1.3 AR模型的应用:线性预测编码器
用N阶AR模型可以仅用N+1个参数(N个滤波器系数和1个白噪声
例如:将一段语音信号
4.1.4 Levison-During递推算法
简称LD算法。AR模型的计算量为
LD算法中引入进了一个额外的参数
4.1.5 AR模型的三组独立参数
对于一个
- 相关函数
到 - 滤波器系数
和白噪声方差 - 反射系数
和自相关函数
4.1.6 AR模型的阶次选择
AR模型很重要的一步就是选择滤波器阶次
- 若阶次过小,得到的功率谱会很平滑,谱分辨率差
- 若阶次过大,得到的功率谱可能有虚假谱峰,还可能产生谱峰分裂现象
4.1.7 AR模型的优缺点
| 优点 | 缺点 |
|---|---|
| 1. 功率谱平滑:AR模型是一个有理分式,使用AR模型得到的功率谱比传统方法更加平滑(毛刺现象更少) | 1. 噪声影响大:分辨率受SNR影响,SNR低时,分辨率明显下降,而传统方法对噪声不敏感 2 |
| 2. 分辨率高:AR模型隐含饿了数据与自相关的预测(也称外推) | 2. 阶次难确定:谱估计质量受阶次影响,阶次难以确定 |
4.2 最大熵谱估计
最大熵谱估计的基本思想是:已知N+1个自相关函数,对
特别的,若均值,方差都固定,则使得熵最大的分布为高斯分布。
需要注意的是,对信号本身的任何处理都不会增加熵。
最大熵谱估计与AR模型的关系:对于高斯随机序列,最大熵谱估计和AR模型等价。
4.3 Capon最小方差法
Capon最小方差法的核心思想是用滤波器
Capon方法估计出来的功率谱与原功率谱的关系仅限于峰值处的频率相同,但不能保证峰值幅度相同。
Capon方法与AR模型的关系为:
显然,阶次越高的时候,AR谱估计的分辨率越高,同阶次的Capon估计方法分辨率不如AR模型