论文笔记-Momentum Contrast for Unsupervised Visual Representation Learning
论文链接:https://arxiv.org/abs/1911.05722
1. 前言
对比学习作为从19年开始一直到现在,视觉领域乃至整个机器学习领域最炙手可热的方向之一,它简单、好用、强大,以一己之力盘活了从2017年开始就卷的非常厉害的机器视觉领域,涌现了一大批优秀的工作,MoCo就是其中之一。MoCo作为一个无监督的表征学习的工作,不仅在分类任务上逼近了有监督的基线模型,而且在很多主流的视觉任务(比如检测、分割、人体关键点检测)上,都超越了有监督预训练的模型,也就是ImageNet上预训练的模型,在有的数据集上甚至是大幅度超越。
2. 摘要
MoCo作为学习视觉表征(或者作为特征提取器)的一种无监督学习方式,它将对比学习看成是一个字典查找任务。本文通过队列这一数据结构构造了一个动态的字典,同时使用了一个滑动平均的编码器。这两个操作可以构建一个庞大且具有高度一致性的字典,有利于对比学习的训练。
MoCo作为一个无监督的预训练模型,能够在7个下游任务(分割、检测等)上,而且比如说在VOC、COCO这些数据集上超越之前的有监督的预训练模型,有时候甚至是大幅度超越。
3. 结论
MoCo的结论再一次强调了它在实验上的结果,但是结论中提到,当数据规模从ImageNet-1M(百万级数据集)提高到Instagram-1B(亿级数据集)时性能提升并不明显,也就是说可能存在饱和现象。另外作者在当年就已经有将MoCo与masked auto-encoding结合起来的想法了,也就有了后来的MAE。
4. 引言
无监督学习已经在NLP领域有了广泛的应用,例如GPT,BERT等模型,但在CV领域,有监督学习仍然占主导地位。原因可能在于文本信号与图像信号本质上的区别,文本信号通常是离散的,很容易构建tokenized dictionary来做无监督学习(tokenized指将一个词抽取为某一特征),而图像信号是连续、高维的,这里的连续并不是指像素值的连续,而是指一幅图像必须至少从连续若干个像素来提取特征。举例来说,一个单词具有单独的语义信息,我们可以理解一个单词,也可以理解一个句子或者一段话,但我们无法理解单一的或者极少量的像素值。
前人的工作可以被归纳为构造动态字典(dynamic dictionaries)。字典的key是从数据中采样获得,而本文呢将无监督学习看作字典查询的思想,就是将找到与query尽可能相似的key,并与其它不相似的key区分开来,这一过程是通过最小化对比损失(contrastive loss)来达成的。这也符合对比学习的基本思想:将相似的特征(token)之间的距离尽可能拉近,并在指定范围内将不相似的特征尽可能拉远。注意在对比学习中,一般应指定特征之间的最远距离,否则模型将会难以收敛。这种做法乍一看与聚类或许有部分相似,但二者有实际意义上的区别。首先聚类通常是在整个数据集上操作,但对比学习是在一个batch中每两个样本比较。另外在对比学习中,我们通常会以一个或几个样本作为锚点(anchor),然后计算一个batch中其他所有样本与锚点之间的距离,这种方法不仅可以帮助我们找到最相似的样本,同时也可以帮助我们在不同的任务中使用相同的锚点。
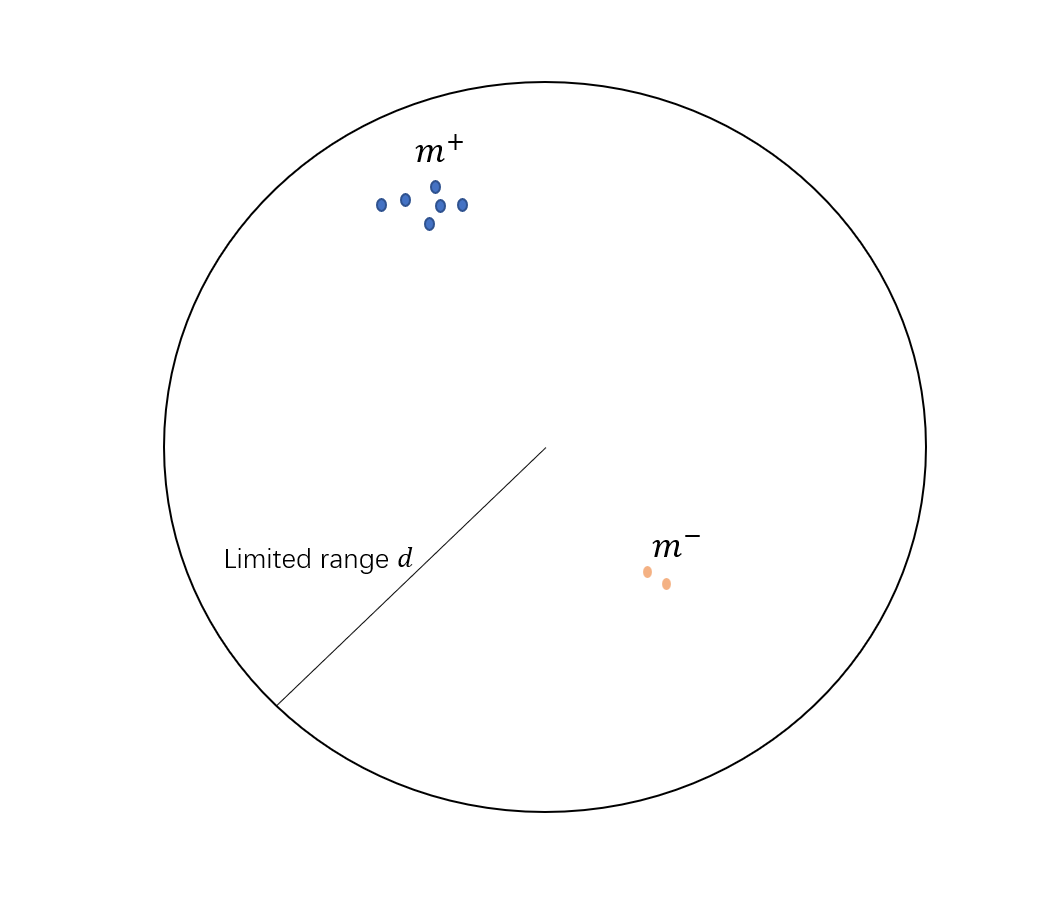
对比学习除了指定anchor,还应当指定至少一个正样本(positive)和若干负样本(negative),这些正负样本组合起来就是文中所说的动态字典。一个好的动态字典应当具备两个性质:
- 丰富性(large),即一个字典应当有足够多的样本;
- 一致性(consistency),即一个字典中的元素应当来自相同或相似的编码器。
首先,大字典可以更好的采样连续和高维的特征,字典中key越多,能表示的视觉信息越丰富,更容易找到具有区分性的本质特征,若词典过小,模型可能学到的是shortcut,泛化能力差,容易过拟合。其次,一致性可以保证query和key做对比是所有的key保证语义的一致性,若字典不一致,模型可能将anchor与其它编码器生成的key的距离拉近,而不是实际拥有语义近似的key。用简单的话来说,假如要找出一个班当中最优秀的一批人(正样本),那就应该从同一个老师(编码器)教的人当中找,而不是和另外的老师教出来的学生做对比,这样才能保证筛选的公平性。
MoCo用队列(queue)的方式来储存这个字典,队列是一种常用的数据结构,具有先进先出(FIFO)的特点。在MoCo中,当前mini-batch中新的编码特征被加入到队列中(enqueue),队列中最旧的编码特征被移除(dequeue)。使用队列数据结构可以将batch size与dictionary size完全分离,也就是说即使batch size很小,我们也能构建一个很大的字典,这就解决了大字典的需求。另外,MoCo采用了一个缓慢更新的编码器,也就是动量编码器(momentum encoder),由于更新速度慢,我们就可以保证每个字典队列中的一致性,具体如何更新将在方法章节中介绍。
对比学习常常会指定一个代理任务(pretext task)作为学习目标。这些代理任务通常不是我们关心的诸如分类、检测等目标,而是针对最终目标创建正负样本对的任务,MoCo选用了instance discrimination作为其代理任务。Instance discrimination是最简单的代理任务之一,以论文中的模型结构图为例,首先将
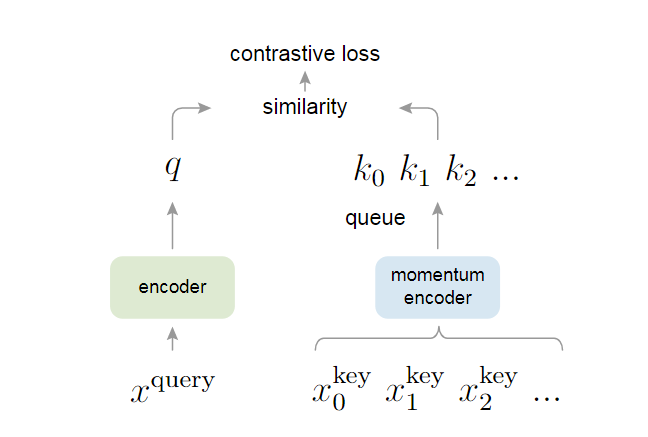
5. 方法
5.1 Contrastive learning as dictionary look-up
对比学习可以看作是训练一个字典查找的编码器。具体做法跟引言最后一段的Instance discrimination相同,关键是字典
和正样本 越相似时,contrastive loss应该越小 和其他所有负样本 都不相似时,contrastive loss应该较小
根据上述两个原则,本文设计了名为InfoNCE loss的损失函数,实际上它就是交叉熵函数的变体,公式如下
这个公式的分子就是正样本的logits,分母则是所有负样本的logits之和,
这里再补充一下NCE loss。在交叉熵函数中,分母的
这里,
为了方便,logits统一用
5.2 Momentum contrast
动量对比,顾名思义就是引入动量来更新参数,其实从信号与系统的角度来理解,动量编码器可以简单类比成一个时序系统,也就是这一时刻的输入依赖于上一个时刻的输出(注意这里的输入输出指的是编码器本身的参数而不是编码器的输入输出)。用公式表示如下
为什么要使用动量编码器呢?我们从两个极端情况来解释,如果动量编码器完全跟query编码器同步,也就是
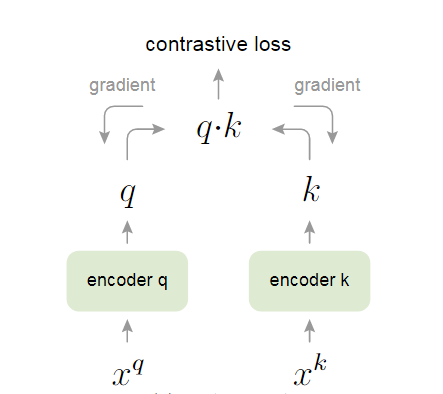
原文中还提到了其他方法,例如端到端学习和memory bank,但这两个方法都会至少受限于两个构造好字典要素的其中一个。端到端学习(end-to-end)受限于丰富性这一条件,这种方法的
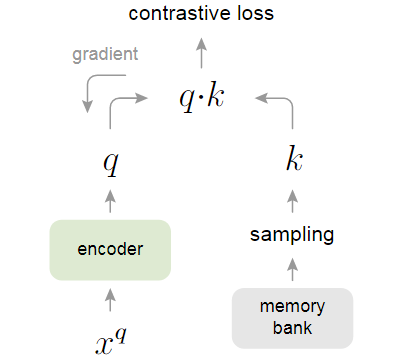
Memory bank方法是牺牲了一部分一致性来保证字典的丰富性。具体而言,memory bank将数据集中所有的样本特征都放在一个字典里,对于ImageNet-1M而言,如果把图像做成128维特征,那就有128万个key,最后需要约600M左右的空间存储。每一次计算loss更新完编码器参数后,memory bank就将这一个batch中的样本重新计算特征,再将其放回原来的大字典做替换。这样虽然保证了字典的丰富性,但每一次更新的特征都来自于不同的编码器,比如batch 1更新了
5.3 Pseudocode of MoCo
到这里MoCo的主要知识点已经讲完了,但对于不熟悉对比学习的朋友来说可能还是不明白MoCo到底是怎样做forward过程的,好在Kaiming大神直接写了伪代码,而且这份伪代码质量相当高,真实的Pytorch代码与这份伪代码相差无几。

首先将query encoder和momentum encoder做初始化,二者初始化参数是相同的,然后做数据增广操作,query和key经过各自的编码器后计算query和正样本
6. 总结
总结下来MoCo一共有两大贡献 1. 如何把字典看成队列 2. 如何用动量更新编码器
MoCo论文里有一句非常重要的话:
1 | A main goal of unsupervised learning is to learn features that are transferrable. |
无监督学习的主要目的是学习到可迁移的特征。因此作者也在原文中做了许多下游视觉任务,都取得了良好的效果。