论文笔记-Masked Autoencoders Are Scalable Vision Learners
论文链接:https://arxiv.org/abs/2111.06377
1. 标题
Kaiming大神的这篇文章采用了“...are...”式的标题,这种标题是一种强力且客观的句式,用一句话就解释了结论。标题中masked表示借鉴了BERT的思想,autoencoders表明了使用自编码器。机器学习中auto一般指“自”而非“自动”,如自回归,意思是
2. 摘要
摘要第一句话是对标题的扩展,说明了MAE是基于self-supervised为CV服务的模型。然后说明了MAE的原理很简单,MAE随机对一些输入图像的pactches做掩码操作,并尝试重建丢失的像素。MAE基于两个核心设计:
- 使用了非对称的encoder-decoder结构,encoder只对未被掩码的patches操作,而decoder是一个轻量化的(lightweighted)的模型,它的作用是尝试恢复被掩码掉的patches。
- 大规模掩码掉原图像中的patches后再做像素重构是一个非显然且有意义的(nontrival and meaningful)的自监督学习任务。
结合上述两个设计可以使得训练效率和结果的准确性大幅提升。A vanilla ViT-Huge在只使用ImageNet-1K训练的情况下取得了87.8%的准确率。此外MAE在迁移学习上也表现得非常好。
3. 导论
先说一下写作手法,这篇文章的导论采用了问问题-回答问题-提出想法的写作方式,很值得学习。首先提出问题
1
What makes masked autoencoding different between vision and language?
- 结构不同。CV领域在当时仍然大规模使用CNN,而在为图像添加mask之后,卷积核无法区分边界(无法将mask的部分提取出来),导致掩码信息难以还原。
- 信息密度不同。NLP中一个词即为一个语义的实体,但图像中信息会有冗余,因此只缺少少数像素块时可以通过临界像素插值来补充,这样MAE就失去了实用价值。因此MAE尝试抹掉了大部分的图像信息(75%)。
- 解码器扮演的角色不同。NLP中还原句子中的词属于高级语义信息,但CV中还原的像素属于低级语义信息。
对于图像分类或者目标检测,decoder使用一个简单的全连接层即可。但对于像素级输出,需要更为复杂的decoder。
基于上述分析,原文提出了一种可扩展的带掩码的自编码器MAE。它使用了非对称的encoder-decoder结构,encoder只作用于可见的patches而decoder尝试恢复像素。同时mask掉大量的patches,这个操作可以创建一个双赢的局面:既减少了计算量,又提高了准确性。
导言的最后卖了一下结果,说明MAE不只是在图像分类上效果优秀,在迁移学习上,例如目标检测和实例分割,也可以取得好结果。下图展示原文中MAE的结果,可以看出在缺少大量的图像信息的情况下依然可以还原的很好。

4. 方法
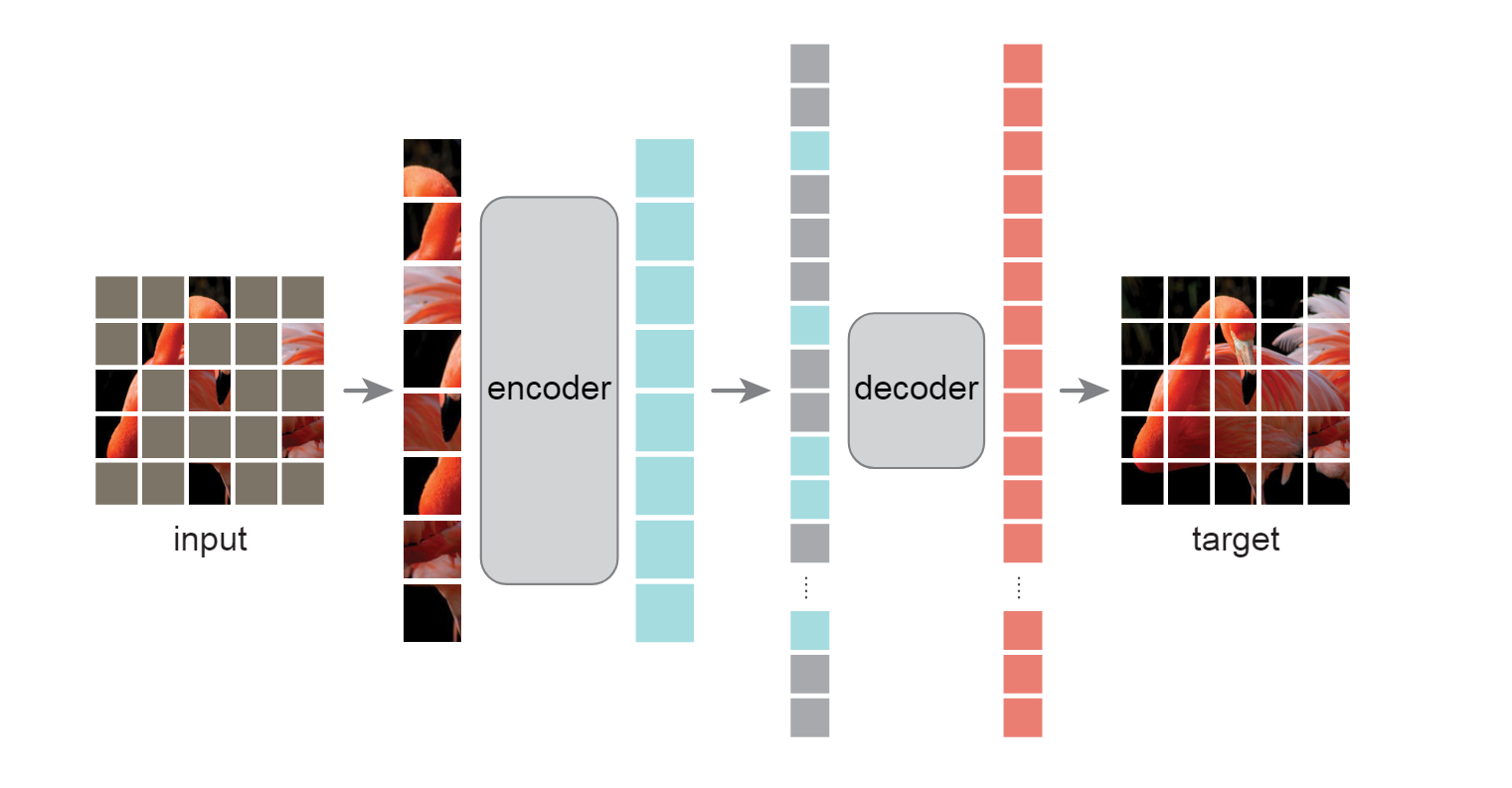
4.1 Masking
跟ViT相同,MAE首先将图片分为若干patches,然后随机采样其中的少量占比的patches即可,其余部分都。需要注意的是,MAE对大多数patches都做了掩码,这样可以消除图像的冗余信息,避免模型只需要用简单的插值就可以还原图像。同时大规模的掩码使得decoder的架构可以变得很简单,因为encoder只关心没有被掩码的部分。
4.2 Encoder
MAE的encoder就是ViT的encoder,唯一的区别就是只有未被掩码的patches被输入了encoder。
4.3 Decoder
Decoder除了接收来自encoder的编码之外,还要接收被掩码的部分。每一个被掩码的patch都是一个相同且可学习的向量。在加入mask部分后,再加入位置编码即可。需要注意的是,MAE的decoder只用在预训练阶段来完成图像重建任务,也就是说encoder的输出可以用来迁移到其他任务上。因此MAE提供了一个可以灵活设计且独立于encoder的decoder结构,针对不同任务decoder可以设计的非常简单或者复杂,与encoder形成了非对称(asymmetric)的结构。
4.4 Reconstruction target
MAE重建mask是通过预测每一个masked patch中的像素来实现的。Decoder的输出是一个被展平的向量,该向量的元素就是预测的像素值。因此,decoder的最后一层是一个线性投影,该层的输出通道与每个patch中像素点的数量相同。
MAE的损失函数采用的是均方误差(Mean squared error, MSE),即计算输出像素与被mask像素的L2误差。
4.5 Simple implementation
首先通过ViT的encoder对划分的每一个patch生成对应的token,然后将这些token进行随机排列(shuffle)操作,最后取前25%比例的tokens,将后面的全部去除。这个操作可以产生一个原tokens的子集,并且等效于对原来的patches直接做采样。采样后将所有去除的部分填充为相同的向量,之后再进行还原(unshuffle)操作来确保tokens与他们的目标一一对应。
5. 评论
MAE算法并不难,它就是将BERT应用到CV领域做自监督学习。总的来说,MAE这篇文章work很充足,写作水平也很高,所以除了算法核心思想外,也可以学到一些论文写作上的技巧。