论文笔记-Swin Transformer:Hierarchical Vision Transformer using Shifted Windows
论文链接:https://arxiv.org/abs/2103.14030
1. 摘要
Swin Transformer一文的主要目的是构造一个可以作为视觉任务通用的backbone架构。之前的ViT已经在图像分类上取得了优秀的结果,而Swin Transformer的诞生使得诸如目标检测、实例分割等下游视觉任务应用Transformer成为可能。要将Transformer运用到下游视觉任务主要面临两个挑战,第一个便是在ViT中也提到的图像序列过长的问题,第二个是物体的多尺度问题。尺度问题是指同一物体在不同场景的大小、形状或者相对位置都有可能不同,这个问题在NLP任务中是不存在的。因此,原文提出了一种与滑动窗口(Shifted windows, Swin)结合的Transformer结构。滑动窗口借鉴了CNN的思想,首先将self-attention计算限制在一些不重合(no-overlapping)的区域来降低序列长度,同时通过shift操作使用cross-window connection来学习全局信息。另外,原文提出的hierachical结构使得模型复杂度随着图像分辨率增加而线性增加(ViT为平方增加)。
2. 导论
Swin Transformer的导论前两段与ViT差不多。导论的核心内容是与ViT在多尺度问题上做了对比。在阐述原文的对比之前,先回顾一下CNN的多尺度特征假设:CNN可提取多尺度特征的主要原因是有多层卷积和池化操作,每一个卷积层的感受野(receptive field)是不同的,并且如果在多层的CNN结构中加入池化操作,越到后面卷积核的感受野将会越大,因此CNN能通过靠后层的卷积操作学习到多尺度特征,例如在目标检测任务中,特征金字塔(Feature pyramid network, FPN)就是用不同卷积层输出的不同level的特征图来学习多尺度特征。总之,对于下游视觉任务,多尺度问题是至关重要的。
ViT产生的特征图都是单一尺寸且是低分辨率的(下采样16倍),因此它并不适合做密集预测型任务。并且ViT始终是在全局图像上做self-attention计算,复杂度随图像分辨率增大而呈现
Swin Transformer为了解决上述问题,借鉴CNN的思想,提出了滑动窗口结构,在每一个local window内做self-attention,引入了CNN中locality的这一归纳偏置(inductive bias)。另外还模仿CNN中的池化操作,提出了patch merging操作,将多个相邻的小patches合成大的patch,相当于做下采样(原文中做的2x下采样)。下图表示了Swin Transformer和ViT生成特征图的区别,可以看出,通过patch merging的操作可以生成不同尺度的特征图,将这些不同level的特征图输入到FPN或者UNet就可以做目标检测或者实力分割了。
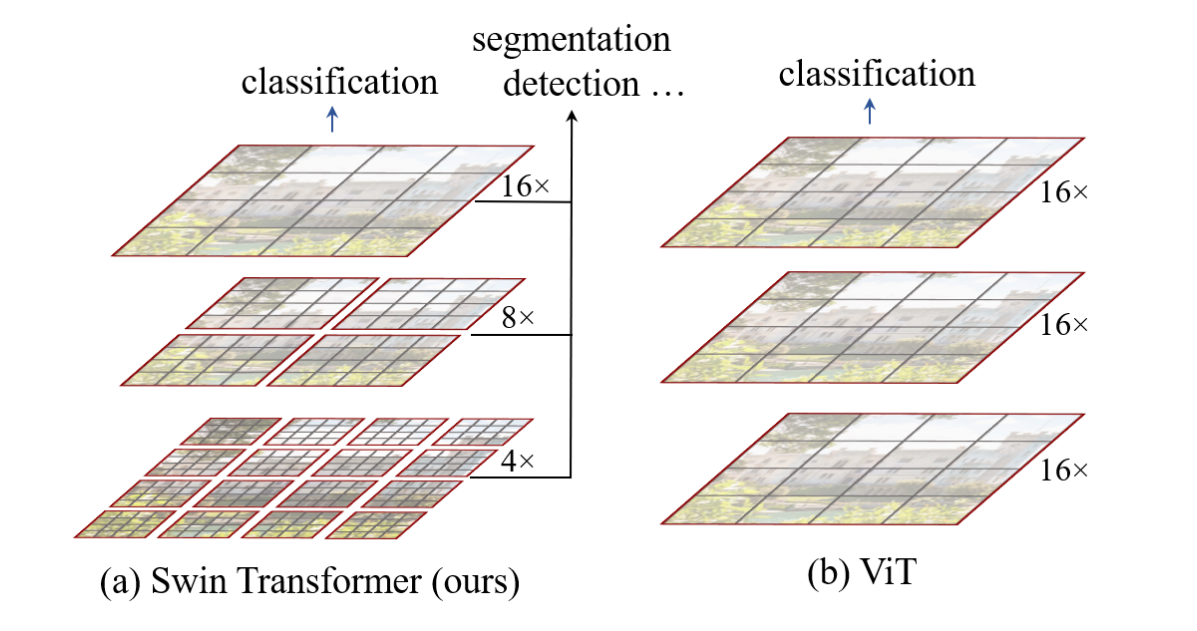
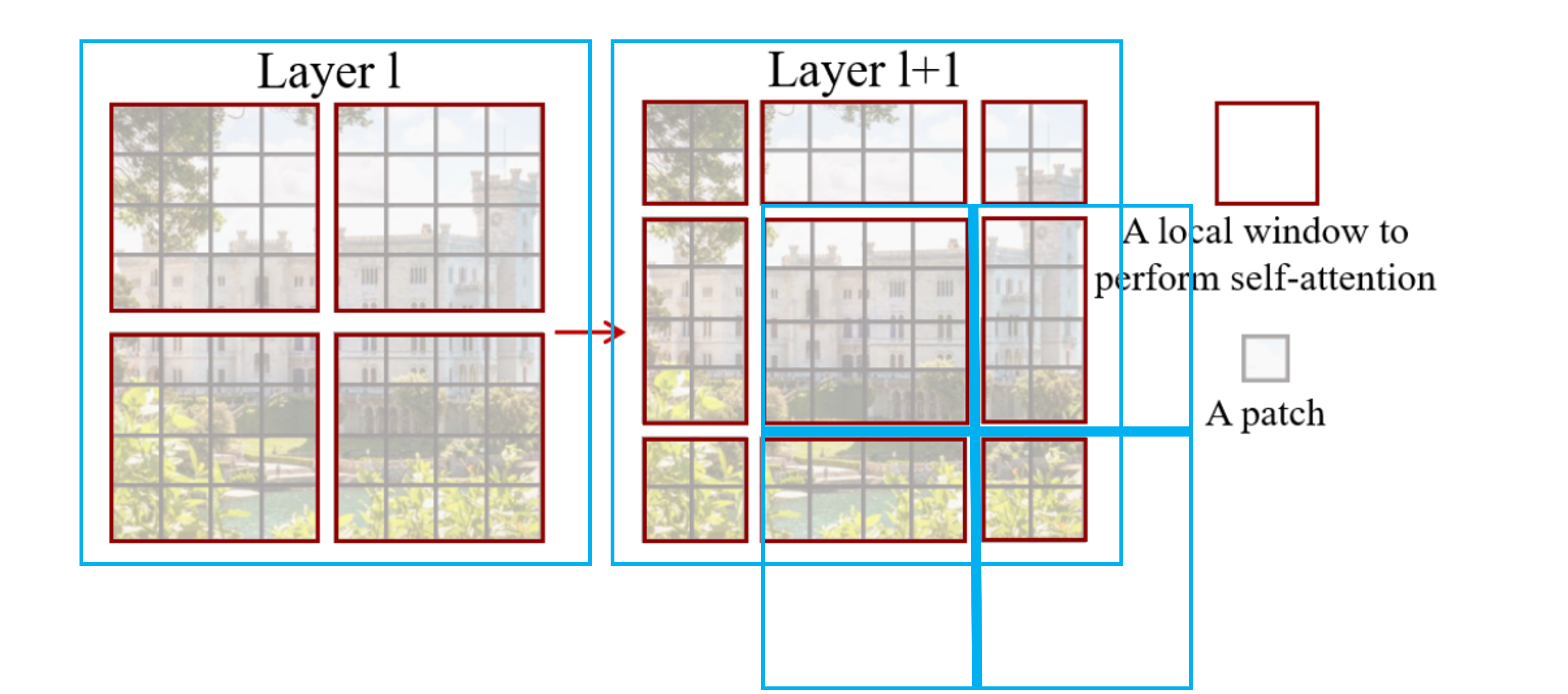
Swin Transformer的核心在于它的滑动窗口(shifted
windows)结构。下图展示了shifted
windows的过程,假设原图用蓝色框表示,那么在第
3. 方法
3.1 模型概览
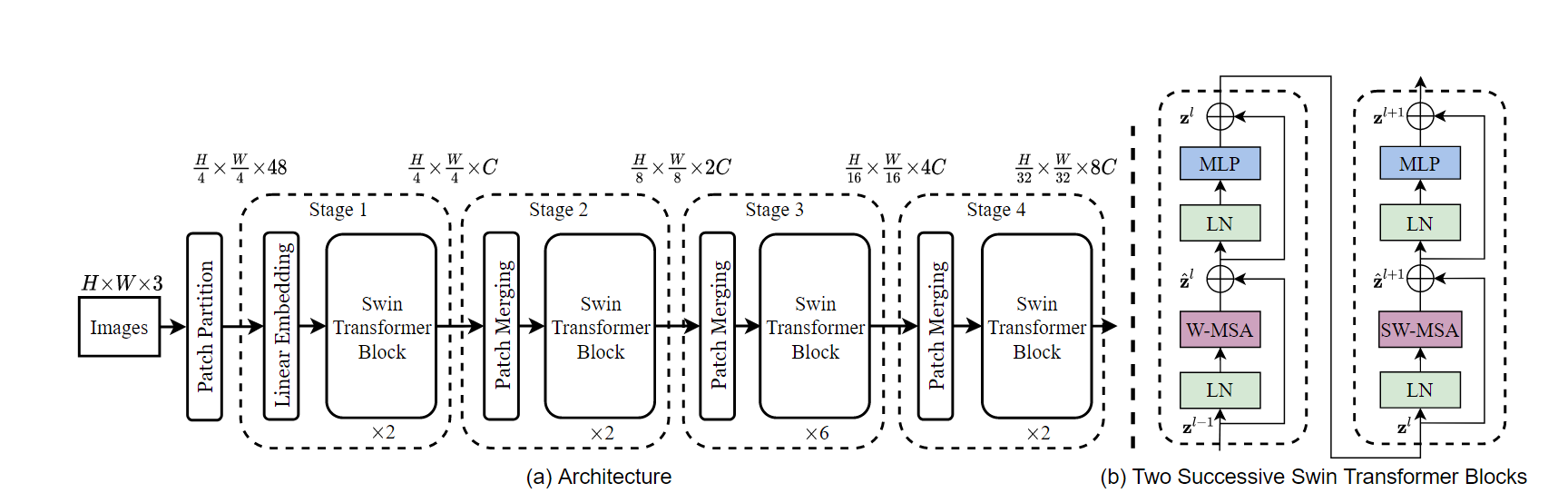
下图展示了Swin Transformer的整体模型架构,跟Attention is all you
need一文的笔记一样,这里先对整体进行描述。仍然假设输入图像为
Stage 1中的Linear
embedding层原理与ViT相同,不过这里将输入投影为到了96维,经过Linear
embedding并展平后输入向量为
Stage 2,3,4都是首先经过一个patch merging操作再连接一个Swin Transformer block,现在暂时可以先将patch merging想象成一个池化层,目的是为了增大self-attention的感受野。
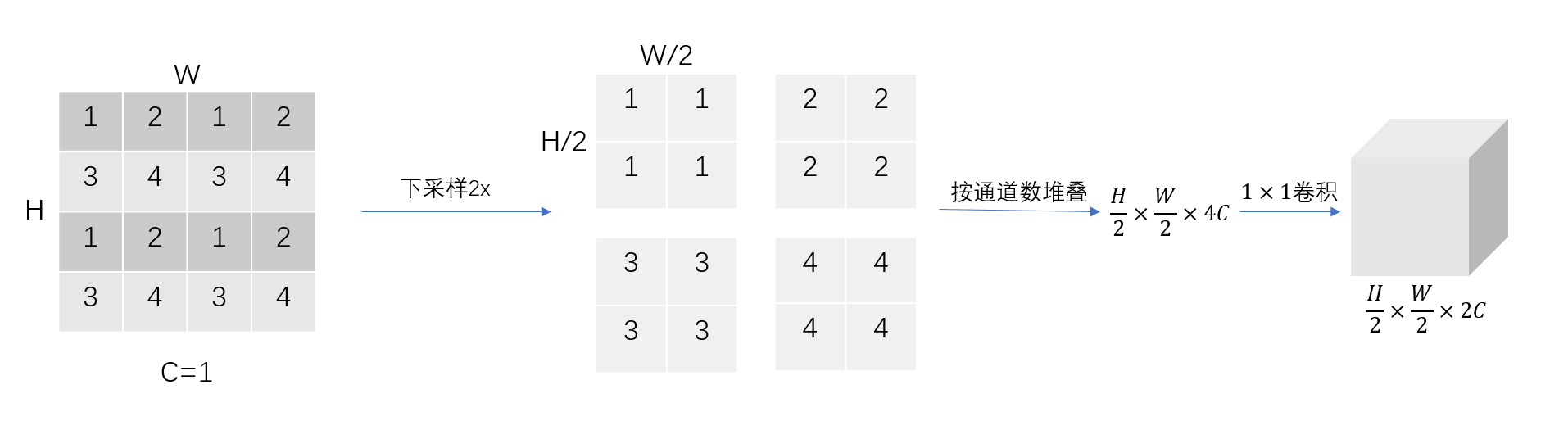
3.2 Patch merging
Patch merging是借鉴CNN池化的思想,用于增大感受野。Patch
merging的过程如下图所示。假设输入为通道
Patch merging的作用是缩小特征图分辨率,调整通道数,最终形成层次化设计(hierachical design)。与CNN的池化操作不同的是,虽然patch merging增加了计算量,但并不会丢失特征图的任何信息。
3.3 Shifted window based self-attention
3.3.1 Computation amount
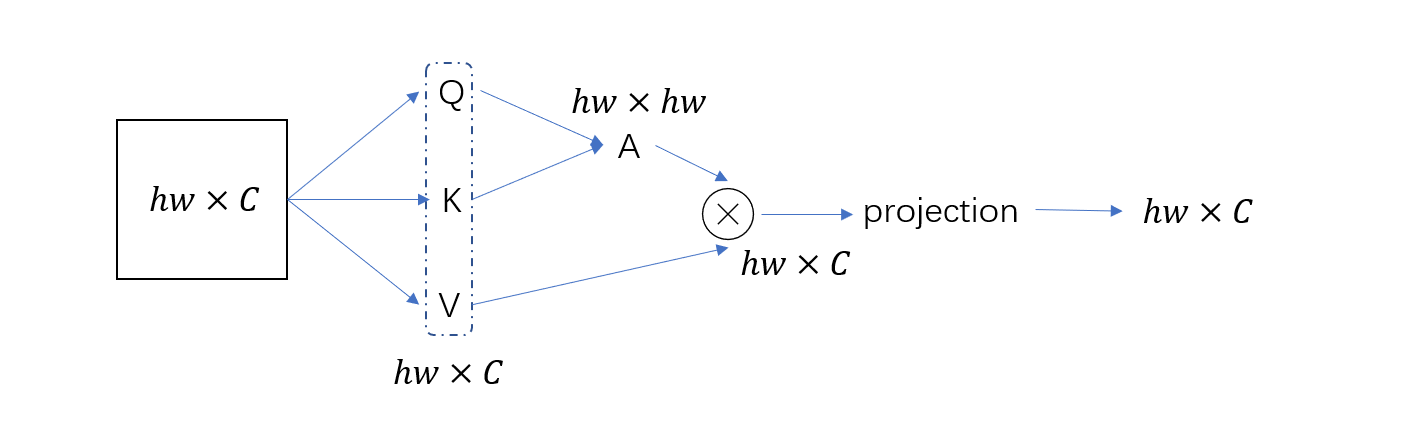
用一句话表述基于窗口的self-attention就是:在划分的每个local
window内做self-attention。原文设定每个窗口为
普通的attention计算维度变化如下图所示。第一阶段,计算
W-MSA的attention计算全部在窗口里,每个窗口有M个patches,那么MSA计算量公式中的
3.3.2 Shifted windows
滑动窗口是整篇文章最核心的思想。通过滑动窗口,Transformer就可以像CNN一样得到图像的相邻特征,相当于人为给Transformer加入了CNN中locality这一归纳偏置。
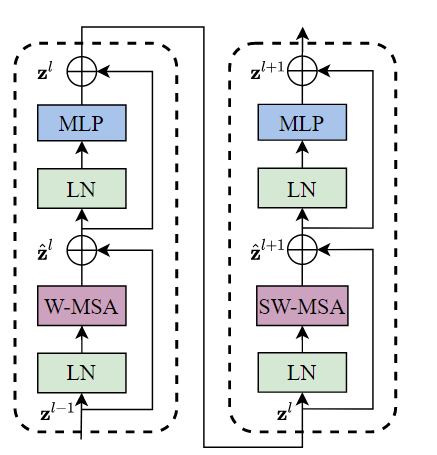
首先应当指出,只在local window内做self-attention计算是无法得到相邻特征的,也就无法进行全局建模。因为不同窗口内patches是相互独立,无法进行attention操作的。因此每一个Swin Transformer block内除了W-MSA操作,还要连接一个SW-MSA(Shifted Window-MSA)模块来保证Transformer能学到不同窗口内的邻接特征,如下图所示。每个block由两个修改过的attention模块串联组成,每个attention模块内除了将MSA模块改为W-MSA和SW-MSA外其他操作均一样。
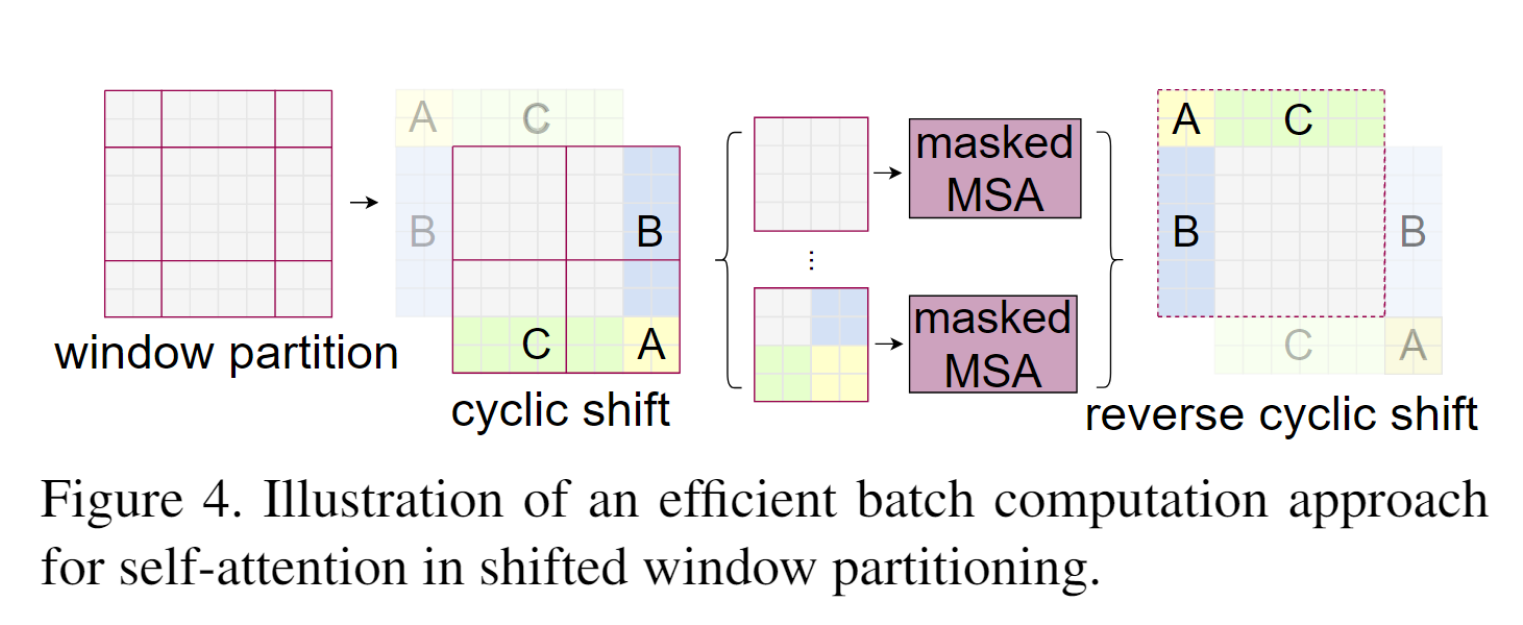
Swin Transformer中的滑动窗口操作如第2节图“滑动窗口”所示,每一次向右下角滑动两个patch后再重新分配窗口。这样做的问题是每个窗口大小不相同,也就不能压成一个batch。一个简单的方法是直接在空白区域pad上0,但这样就把原先的4个窗口增加到了9个窗口,计算量提高了。
原文提出了一种非常巧妙地掩码方法,既可以保证每个batch内只有4个窗口,又可以保证每个窗口内的patches数量相同,过程如下图所示。原文首先将窗口移位之后没有被划进窗口内的patches移动填补到空白区域。这样就可以保证每一部分都是有效信息且每个窗口内的patches数量一致。但这也会引入一个新的问题,移位之后的图像的相对位置相较于原来的位置有所变化,把他们强行与图中其他区域一起做self-attention操作是不合理的。例如,一幅图中A部分原本为天空,C部分为地面,经过移位之后,天空与地面就连接在一起了,这显然是不符合认知的,所以要进行掩码操作。
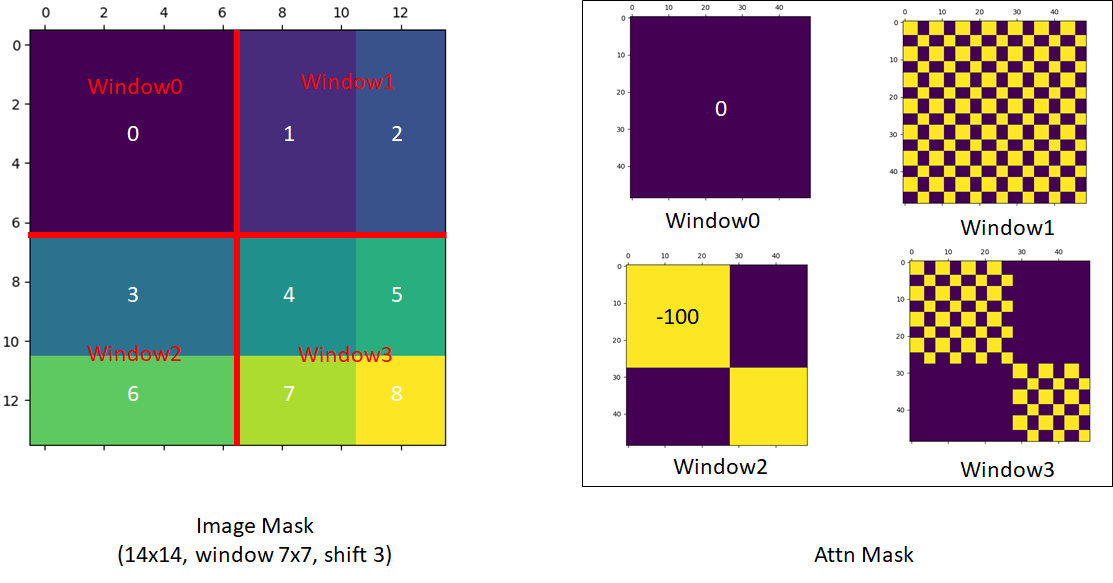
Swin Transformer的GitHub仓库issue 38中也提出了有关mask的问题,原作者给出了如下的可视化移位之后的窗口图。直接看图可能有一些模糊,这里也借用b站up主大神Bryanzhu的讲解。以图片左下角window2为例,window2中上半部分为原图中的3,下半部分为从其他地方移位过来的6,将window2中展平为向量和它做self-attention操作可以表示为自己和自己的转置相乘(注意这里3和6表示矩阵内元素,不表示具体数值),得到的结果可以表示为一个分块矩阵。现在我们只需要33和66的部分的attention,而不需要36和63的部分,因为36个63这两部分来自图像不同位置,不需要self-attention操作得到的值。具体操作为在得到的分块矩阵上加上一个掩码矩阵,这个掩码矩阵在需要的地方填充0,不需要的地方填充为-100(或者一个很大的负数),这样在softmax操作的时候不需要的部分被放到指数上就趋近于0了。下式为window2的掩码操作,其他windows的操作相同,只是根据self-attention的结果变换一下掩码矩阵0和负数的位置即可。计算后还要做一个反向移位,不然整个图像随着层数的递增会一致往右下角移动,这样会破坏语义信息。
4. 评论
Swin Transformer可以被认为是套了Transformer外套的CNN,因为它将CNN中两条重要的归纳偏置加入了Transformer中,使得Transformer可以提取到相邻特征,增大感受野。
Swin Transformer不仅仅是可以用来做图像分类,原作者更希望它能成为一个CV领域通用的backbone,我们完全可以将Swin Transformer当成一个特征提取器,然后自己设计抽头。到这里,NLP与CV模型大一统的进程又向前推进了一步。