论文笔记-An image is worth 16x16 words: Transformers for image recognition at scale
论文链接:https://arxiv.org/abs/2010.11929
1. 摘要
Transformer在NLP任务中已经成了最为主流的模型,但它在CV领域的应用却比较受限。视觉任务仍然主要采用CNN架构,或者一些改进结构中引入了Attention模块。但这篇文章只使用了Transformer结构,完全抛弃了CNN结构,将一张图片分为多个patch sequences作为输入,在大规模数据集上做预训练并在小数据集上做微调,最后在图像分类任务上取得了优异的结果。
2. 导论
self-attention已经成为了NLP领域必选的结构,主流方式是在BERT一文中提出的,随着模型和数据集的增大,使用了self-attention架构的Transformer即使到文章发布的时候仍然没有饱和的现象。在self-attention结构中,输入为一串维度为
现有的做法有结合CNN和self-attention的结构,例如将用CNN提取的特征图(Resnet50最后的特征图一般为
此外相比于CNN,Transformer对模型的归纳偏置(inductive biases)几乎没有,因此需要庞大的数据集进行预训练,否则效果将不会太好。有关Transformer与CNN的归纳偏置将会在后面单独讨论。
3. 方法
ViT的核心思想与普通的Transformer完全相同,结构方面有区别的地方仅在于使用了简单的MLP head代替了NLP任务中的decoder,因为图像分类任务不需要,下图给出了ViT的模型结构。
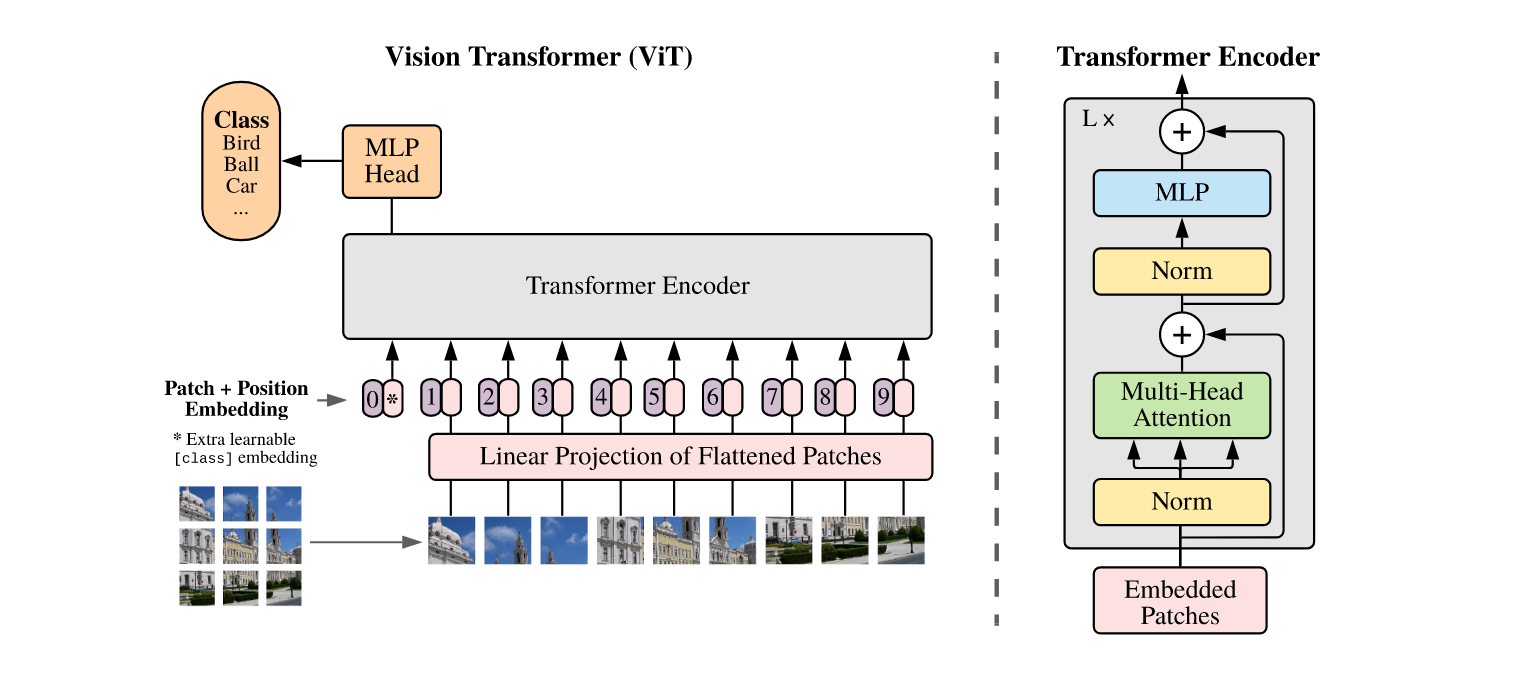
3.1 Image to sequence
ViT最重要的思想在于它预处理图像的方法。ViT将一幅图片(文中采用的是比较通用的
对于RGB图像,每个patch有
3.2 class token
在BERT中,除了句子本身的序列外,还引入了一个class token来表示对句子全局理解的特征,同样,ViT为了保证自身与原始Transformer尽可能相同,也引入了class token来表示一幅图像的全局特征,这个class toke的长度也为768,在输入进Transformer encoder之前直接拼接到输入向量中去作为第0个token。class token是一个随机初始化的可学习参数,当然也可以全部初始化为0。class token也将作为最终encoder的输出送入MLP head中进行分类。
引入class token有主要有两个好处: 1. class token是所有图像块的信息聚合,是独立于image sequence存在的,不会偏向于某一个特定的patch。 2. 由于class token始终处于所有patch的前方,即使其他patch的位置编码会改变,class token的编码不会改变。
对比于Resnet来说,Resnet本身是在最后用全局平均池化(global average
pooling, GAP)来将得到的
加入class token后Transformer encoder的输入就如下式,其中
3.3 Positional encoding
与普通Transformer一样,self-attention模块每一次计算的都是全局信息,因此无法提取图像中的位置信息。显然将一幅图像打散后每个子图块之间存在位置关联,譬如物体与物体之间的相对位置,因此需要加入位置编码。
原文中提到了3种位置编码:1d编码、2d编码和相对编码。其中1d编码与Attention
is all you
need一文中提到的位置编码完全相同。2d编码则是将一维位置信息转化为包含
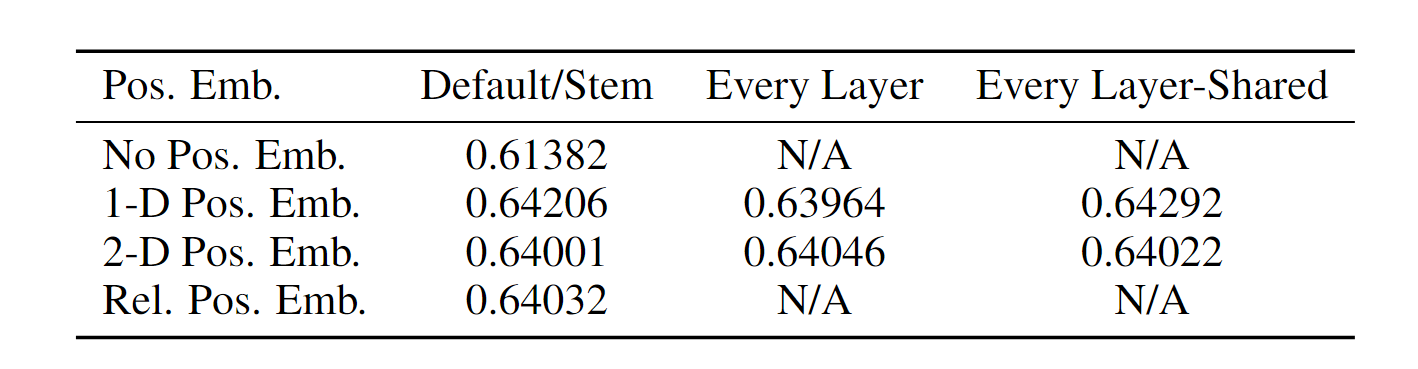
但实际上原文中也提到,使用1d与2d的位置编码对最后结果影响不大,原文中给出了不同位置编码对结果的影响,如下表所示。可以看出有没有位置编码对结果影响是比较大的,但位置编码的种类对结果影响不大。
3.4 Inductive bias
Transformer并不像CNN一样有归纳偏置。CNN的归纳偏置有局部性(locality或者two-dimensional neighborhood)和平移不变性(translation equivariance)。
局部性是指CNN假设两个滑动窗口之间存在相邻特征,所以才能用卷积核进行逐块卷积。而平移不变性是指图像经历平移或者卷积的顺序不会影响最终结果,即
Transformer由于没有上述归纳偏置,而归纳偏置相当于为模型加入了先验信息,所以Transformer在小数据集上的结果不如以CNN为基础的Resnet。但Transformer在大规模数据集上的表现是非常好的。
3.5 Hybrid architecture
原文中作者还进行了一种混合模型的测试,也就是将CNN提取出来的特征图通过Linear projection转换为sequence。这种混合模型在中小数据集上是比单Resnet或者Transformer的结果要好的,但随着数据集的扩大,这种混合模型也展现出了到达饱和的现象,而纯的Transformer是没有的。个人胡乱推测是因为CNN已经达到了极限,拖了Transformer的后腿。
3.6 Fine-tuning and Higher resolution
前面提到,Transformer更适合在大规模数据集上做与训练,再在小数据集上进行微调。这会引入一个新的问题,用更高分辨率的图像做训练时,序列会变长,计算量会增加,而且由于patch位置编码变得不再可用。一种临时解决方案是使用Pytorch自带的2d插值操作为缺省的位置编码做插值,但在与训练模型使用的位置编码和微调使用的位置编码维度相差过大时,2d插值也会引入很大的数据噪声。这一部分原文没有给出进一步解决方案,留给后来的研究者们深入讨论。
4. 评论
ViT真的是挖了很大的坑,从任务上说它只做了图像分类,那么很显然可以延申到其他任务中去
(也就是下一篇博客要写的Swin
Transformer),此外还可以对Transformer的编码形式,block的内部结构做调整。另外ViT这篇文章本身是用的有监督学习,那么很显然可以将其运用到自监督学习、对比学习之类的半监督学习和无监督学习上。最重要的是ViT架起了NLP和CV之间的桥梁,为新的多模态学习奠定了新的基础。