论文笔记-Attention is all you need
论文链接:https://arxiv.org/abs/1706.03762
1. 摘要
Transformer结构出来之前对于序列转换(sequence transduction)主要依赖于带有encoder-decoder结构的RNN和CNN,当然也有一些模型也使用了attention机制来来连接编解码器。但是这些模型都有一个共同的问题,就是它们的计算复杂度随着序列长度的增加而呈指数级增长,这使得它们在处理长序列时变得非常困难。Transformer模型是第一个完全使用attention机制来进行编码和解码的模型,它的计算复杂度与序列长度成线性关系,因此可以很好地处理长序列。
2. 结论
Transformer是首个只是用attention机制的序列转换模型,主要使用了multi-headed self-attention模块。作者预测将来Transformer将会被运用除了文本以外更多领域(而事实也确实如此)。
3. 导论
RNN的特点是在计算时间步
Attention机制的特点是可以使模型纵观全局输入而不依赖于时间步的关系,因此attention可以忽略输入序列之间不同词语的距离,这也为并计算提供了可能。
Transformer只依赖于attention机制,去除了循环结构,并行度高,在较短时间内获得了很好的结果(8 P100 GPUs,12小时训练)
4. 背景(相关工作)
CNN也可以用来减少sequential
computation。但由于CNN的感受野(窗口)大小是有限的,通常为
本文提出了self-attention机制,它是一种将一个序列中不同位置关联起来,从而达到表达这个序列的机制。
5. Attention机制
Attention机制可以表达输入序列不同词语之间的关系,实际上就是一组向量的加权求和。Attention机制的核心计算是基于三个矩阵:<key, value>可以组成一个source(可以理解为一个键值对),现在来了一个查询请求query,那么就应该将query与每一个key做对比,也就是计算相似度,然后再与value做加权求和,这样就可以得出这一个query与source中的哪一个键值对最相似,然后再赋予该值最大的权重即可,需要注意的是key和value的值可以是相同的,也可以是不同的,在机器翻译下的self-attention中,key和value的值是相同的。下图可以表示attention权重的计算过程。
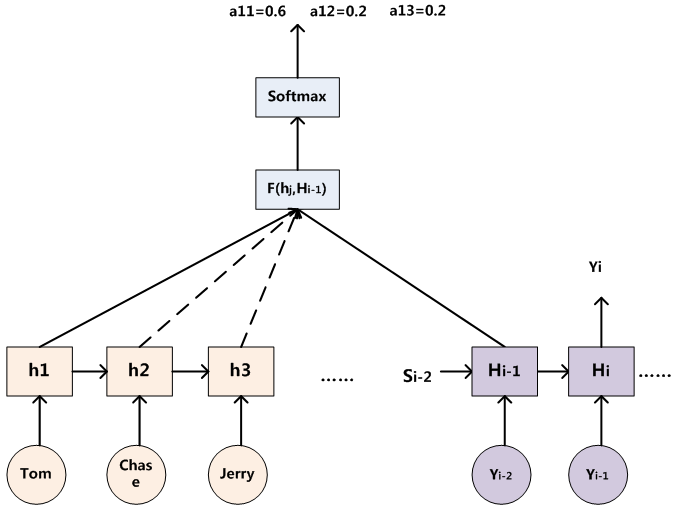
这里单词Tom可表示query,在encoder中,它可以与decoder中的所有隐藏状态
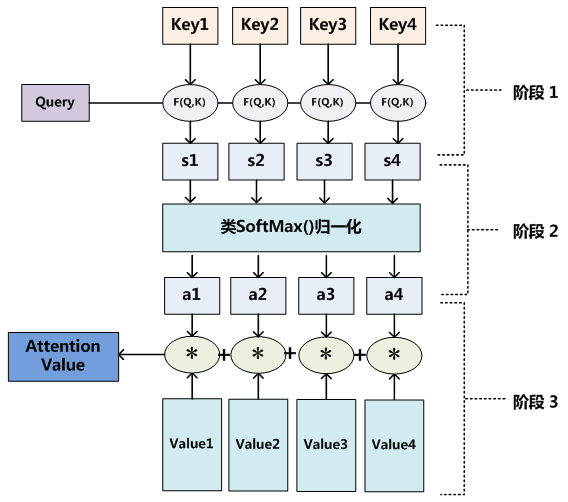
用公式描述则为
上式中
6. 模型架构
6.1 概述
假设有一组输入
6.2 Encoder-Decoder架构
论文中的图清晰的给出了一个Encoder-Decoder架构的图,这里首先对这张图做整体描述,再详细解释每一个模块。该图中的左侧为encoder,输入首先经过一个embedding层,加入位置掩码(Positional
encoding)后输入encoder,encoder中包含了一个多头注意力模块(Multi-head
attention),并且做了残差连接,之后送入一个前馈的MLP并也进行残差连接后完成编码。右侧的decoder下方输出也先经过一个embedding层,这里shifted
right指的是decoder会将之前的输出作为这一时刻的输入。同样,decoder中也加入了位置掩码,并将输出向量送入一个带有mask的multi-head
attention模块中,该模块经残差连接以及layernorm后的输出则作为下一个multi-head
attention输入中的
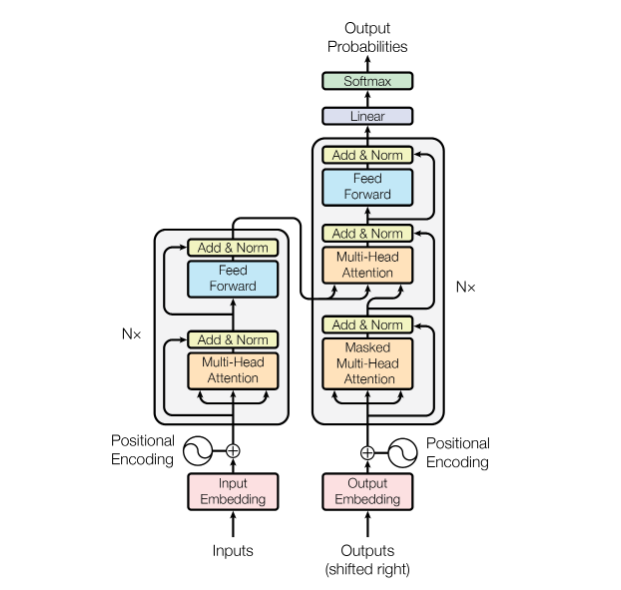
6.3 Positional encoding
位置编码(Positional
encoding)的作用是用来引入时序信息。因为Transformer在处理机器翻译任务时,attention机制可以感知模型内部所有的信息,也就是说,模型在输出
公式中
6.4 Attention
本文中的attention机制原理与第五节相同,其独特的地方在于使用了scaled
dot-product。具体公式如下,
这里首先阐述每个矩阵的维度问题。因为
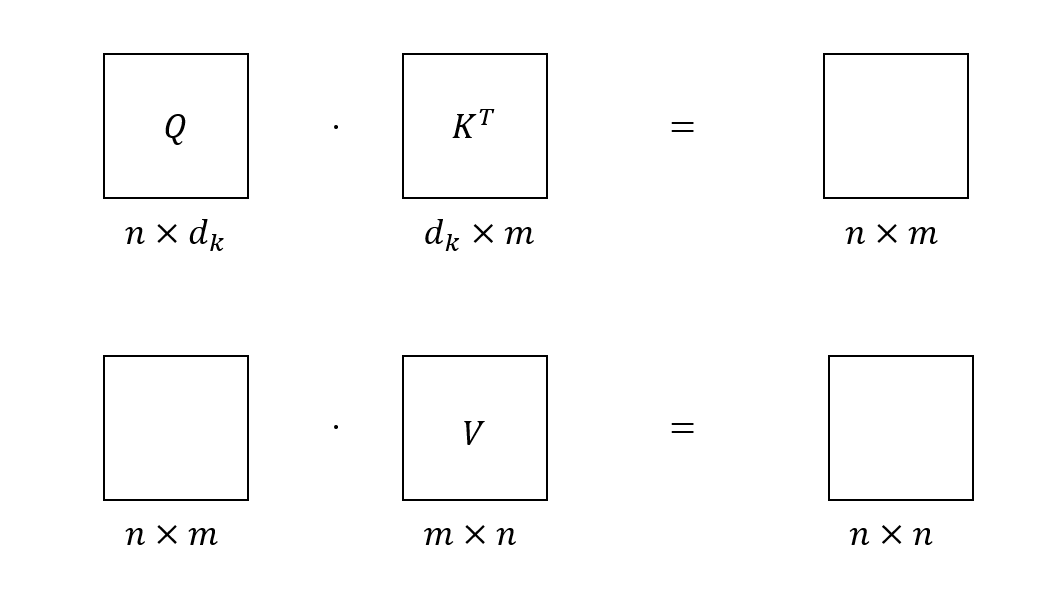
当
在Transformer的编码器中使用的是self-attention模块,即
6.5 Multi-head attention
多头注意力机制(Multi-head attention)是模仿CNN的多输出通道的模式,将高维的模型输入特征通过线性映射到低维中去,通过很多个低维的attention模块学习到不同的映射模式。在我看来这类似于用ensemble的方式将多个弱分类器集合为一个强分类器。下图表示了multi-head attention模块架构
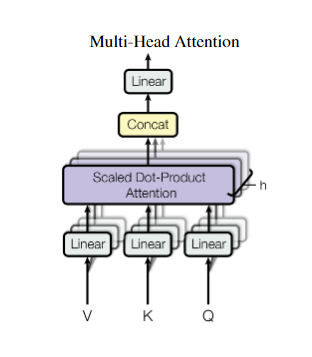
用公式表示则为
6.6 Point-wise feed-forward networks
每一个encoder和decoder模块的最后都引入了一个FFN,该FFN的作用是将attention的结果映射到更高维的特征空间中去,类似于SVM的核函数,可以在高维特征空间中学到更为线性分类器。
FFN的本质上就是一个做了残差连接的MLP,用公式表示为
本文中首先通过
6.7
(Query)矩阵:⽤于⽣成查询向量,决定模型在注意⼒机制中对输⼊的关注程度。 (Key)矩阵:⽤于⽣成键向量,与查询向量计算相似度,帮助确定注意⼒分布。 (Value)矩阵:⽤于⽣成数值向量,实际传递注意⼒机制计算的输出。 (Output)矩阵:⽤于将多头注意⼒的输出合并并映射回原始维度。
信息传播的关键路径
与 的交互: 和 的交互决定了注意⼒分布,影响模型对输⼊序列的不同部分的关注度。 的加权求和: 矩阵通过加权求和操作,将注意⼒分布转化为具体的输出。 - 多头输出的整合:
矩阵整合多头注意⼒的输出,提供最终的特征表示。
7. 评论
这篇文章的确开创了一个新的时代,它摒弃了传统的RNN和CNN架构,只使用了attention机制,在当时证明了除了循环结构和卷积结构外还有其他表现优秀的结构。后来的大型语言模型(Large language model, LLM),如GPT,也普遍采用了Transformer架构,可见其影响力。
但是由于Transformer架构对模型的假设很少,所以需要更大的模型体量和更多的数据训练才能获得理想结果,这对于小作坊来说是非常困难的。这时候就是Money is all you need了。